베스트셀러 데이터 크롤링하기
yes24 크롤링 관련 글 목록
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 01
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 02
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 03
- 데이터 과학을 위한 파이썬 라이브러리 모음
파이썬 패키지 임포트하기
크롤링에 필요한 파이썬 패키지들을 임포트합니다.
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
yes24DataReader 함수 만들기
- yes24DataReader(‘001001047’, ‘2019’, ‘6’)
도서 카테고리 코드와 날짜 정보를 입력하여 관련 데이터를 수집하는 함수를 정의하겠습니다.
| 카테고리 | 코드 |
|---|---|
| 경제경영 | 001001025 |
| 사회정치 | 001001022 |
| 에세이 | 001001047 |
| 역사 | 001001010 |
# 데이터 수집 함수 정의
def yes24DataReader(CategoryNumber, year, month):
root_url = 'http://www.yes24.com'
url_1 = 'http://www.yes24.com/24/category/bestseller?CategoryNumber='
url_2 = '&sumgb=09&year='
url_3 = '&month='
url_4 = '&PageNumber='
url_set = url_1 + CategoryNumber + url_2 + year + url_3 + month + url_4
book_list=[]
# 월 별 조회 시 최대 50쪽이지만, 간단한 설명을 위해 2쪽까지만 수집
for i in range(1, 3):
url = url_set + str(i)
res = requests.post(url)
soup = BeautifulSoup(res.text, 'html5lib')
tag = '#category_layout > tbody > tr > td.goodsTxtInfo > p:nth-child(1) > a:nth-child(1)'
books = soup.select(tag)
# 수집 중인 페이지 번호 출력
print('# Page', i)
# 개별 도서 정보 수집
for book in books:
sub_url = root_url + book.attrs['href']
sub_res = requests.post(sub_url)
sub_soup = BeautifulSoup(sub_res.text, 'html5lib')
tag_name = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > div > h2'
tag_author = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_auth > a'
tag_author2 = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_auth'
tag_publisher = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_pub > a'
tag_date = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_date'
tag_sales = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_ratingArea > span.gd_sellNum'
tag_listprice = '#yDetailTopWrap > div.topColRgt > div.gd_infoBot > div.gd_infoTbArea > div:nth-child(3) > table > tbody > tr:nth-child(1) > td > span > em'
tag_listprice2 = '#yDetailTopWrap > div.topColRgt > div.gd_infoBot > div.gd_infoTbArea > div:nth-child(4) > table > tbody > tr:nth-child(1) > td > span > em'
tag_price = '#yDetailTopWrap > div.topColRgt > div.gd_infoBot > div.gd_infoTbArea > div:nth-child(3) > table > tbody > tr:nth-child(2) > td > span > em'
tag_price2 = '#yDetailTopWrap > div.topColRgt > div.gd_infoBot > div.gd_infoTbArea > div:nth-child(4) > table > tbody > tr:nth-child(2) > td > span > em'
tag_page = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(2) > td'
tag_weight = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(2) > td'
tag_hor = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(2) > td'
tag_ver = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(2) > td'
tag_width = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(2) > td'
tag_isbn13 = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(3) > td'
tag_isbn10 = '#infoset_specific > div.infoSetCont_wrap > div > table > tbody > tr:nth-child(4) > td'
# 기본적인 예외처리를 통한 데이터 수집
name = sub_soup.select(tag_name)[0].text
try:
author = sub_soup.select(tag_author)[0].text
except:
author = sub_soup.select(tag_author2)[0].text.strip('\n').strip().replace(' 저','')
publisher = sub_soup.select(tag_publisher)[0].text
date = sub_soup.select(tag_date)[0].text.replace('년 ','-').replace('월 ','-').replace('일','')
try:
sales = sub_soup.select(tag_sales)[0].text
if '판매지수' in sales:
sales = sub_soup.select(tag_sales)[0].text.strip().strip('|').strip().lstrip('판매지수 ').rstrip(' 판매지수란?')
else :
sales =''
except:
sales = ''
try:
listprice = sub_soup.select(tag_listprice)[0].text.replace(',','').replace('원','')
except:
try:
listprice = sub_soup.select(tag_listprice2)[0].text.replace(',','').replace('원','')
except:
listprice = ''
try:
price = sub_soup.select(tag_price)[0].text.replace(',','')
except:
try:
price = sub_soup.select(tag_price2)[0].text.replace(',','')
except:
price = ''
page = sub_soup.select(tag_page)[0].text
if '쪽' in page:
if '확인' in page:
page = ''
else :
page = page.split('|')[0].strip().replace('쪽','')
else :
page = ''
weight = sub_soup.select(tag_weight)[0].text
if 'g' in weight:
weight = weight[:weight.find('g')].split('|')[1].strip()
else :
weight = ''
hvw = sub_soup.select(tag_hor)[0].text
if 'mm' in hvw:
if hvw.split('|')[-1].strip().count('*')==2:
hor = hvw.split('|')[-1].strip().split('*')[0]
ver = hvw.split('|')[-1].strip().split('*')[1]
width = hvw.split('|')[-1].strip().split('*')[2].replace('mm','')
elif hvw.split('|')[-1].strip().count('*')==1:
hor = hvw.split('|')[-1].strip().split('*')[0]
ver = hvw.split('|')[-1].strip().split('*')[1].replace('mm','')
width = ''
else :
hor = ''
ver = ''
width = ''
try :
isbn13 = sub_soup.select(tag_isbn13)[0].text
if '확인' in isbn13:
isbn13 = ''
else :
isbn13 = sub_soup.select(tag_isbn13)[0].text
except :
isbn13 = ''
try :
isbn10 = sub_soup.select(tag_isbn10)[0].text
if '확인' in isbn10:
isbn10 = ''
else :
isbn10 = sub_soup.select(tag_isbn10)[0].text
except :
isbn10 = ''
book_list.append([name, author, publisher, date,
sales, listprice, price, page,
weight, hor, ver, width, isbn13, isbn10])
print('=========>', name)
# 데이터프레임 컬럼명 지정
colList = ['name', 'author', 'publisher', 'date',
'sales', 'listprice', 'price', 'page',
'weight', 'hor', 'ver', 'width', 'isbn13', 'isbn10']
# 데이터프레임으로 변환
df = pd.DataFrame(np.array(book_list), columns=colList)
return df
역사 베스트셀러의 19년도 데이터 수집하기
역사 카테고리의 2019년도 9월 베스트셀러 데이터를 수집하여, 월 별 CSV 파일로 저장해보겠습니다.
# 역사 카테고리 번호 : 001001010
CategoryNum='001001010'
# 2019년도
for year in range(2019, 2020):
print('='*50)
print('# Year', year)
print('='*50)
# 9월
for month in range(9, 10):
print('='*50)
print('# Month', month)
print('='*50)
# 월 별 데이터 수집
df = yes24DataReader(CategoryNum, str(year), str(month))
# 월 별로 수집된 데이터를 CSV 형식 파일로 저장
df.to_csv(str(year)+'_'+str(month)+'_'+str(CategoryNum)+'.csv', index=False, encoding='CP949')
==================================================
# Year 2019
==================================================
==================================================
# Month 9
==================================================
# Page 1
=========> 반일 종족주의
=========> 유럽 도시 기행 1
=========> 역사의 쓸모
=========> 설민석의 조선왕조실록
=========> 총, 균, 쇠
=========> 일본 제국 패망사
=========> 세계사를 바꾼 13가지 식물
=========> 역사의 역사
=========> 에로틱 조선
=========> 설민석의 무도 한국사 특강
=========> 학교에서 가르쳐주지 않는 일본사
=========> 세계사를 바꾼 12가지 신소재
=========> 나의 한국현대사
=========> 설민석의 첫출발 한국사 연표 (보급판)
=========> 국화와 칼
=========> 나의 로망, 로마
=========> 대한민국 이야기
=========> 본격 한중일 세계사 6
=========> 대한민국 역사
=========> 문명으로 읽는 종교 이야기
# Page 2
=========> 나의 문화유산답사기 : 중국편 1 돈황과 하서주랑
=========> 사쿠라 진다
=========> 유발 하라리의 르네상스 전쟁 회고록
=========> 국화와 칼
=========> 지리의 힘
=========> 나의 문화유산답사기 : 중국편 2 막고굴과 실크로드의 관문
=========> 부의 지도를 바꾼 회계의 세계사
=========> 역사의 색
=========> 조선의 미식가들
=========> 요시다 쇼인 시대를 반역하다
=========> 세종은 과연 성군인가
=========> 오래된 미래
=========> 총, 균, 쇠
=========> 학교에서 가르쳐주지 않는 세계사
=========> 우린 너무 몰랐다
=========> 붕괴
=========> 나의 문화유산답사기 : 산사 순례
=========> 징비록
=========> 35년 1~5 세트
=========> 세계사를 바꾼 10가지 약
df.head(10)
DataFrame 예시
| name | author | publisher | date | sales | listprice | price | page | weight | hor | ver | width | isbn13 | isbn10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 반일 종족주의 | 이영훈 | 미래사 | 2019-07-10 | 277392 | 20000 | 18000 | 416 | 666 | 151 | 211 | 26 | 9788970873268 | 8970873260 |
| 1 | 유럽 도시 기행 1 | 유시민 | 생각의길 | 2019-07-09 | 327258 | 16500 | 14850 | 324 | 517 | 145 | 210 | 20 | 9788965135586 | 8965135583 |
| 2 | 역사의 쓸모 | 최태성 | 다산초당 | 2019-06-14 | 226404 | 15000 | 13500 | 296 | 482 | 147 | 218 | 20 | 9791130621968 | 1130621960 |
| 3 | 설민석의 조선왕조실록 | 설민석 | 세계사 | 2016-07-25 | 235818 | 22000 | 19800 | 504 | 991 | 165 | 235 | 30 | 9788933870693 | 8933870695 |
| 4 | 총, 균, 쇠 | 재레드 다이아몬드 | 문학사상 | 2005-12-19 | 101616 | 28000 | 25200 | 752 | 950 | 148 | 210 | 40 | 9788970127248 | 8970127240 |
| 5 | 일본 제국 패망사 | 존 톨랜드 | 글항아리 | 2019-08-12 | 10161 | 58000 | 52200 | 1,400 | 1,878 | 153 | 224 | 80 | 9788967356521 | 8967356528 |
| 6 | 세계사를 바꾼 13가지 식물 | 이나가키 히데히로 | 사람과나무사이 | 2019-08-08 | 30504 | 16500 | 14850 | 296 | 506 | 140 | 215 | 20 | 9791188635214 | 1188635212 |
| 7 | 역사의 역사 | 유시민 | 돌베개 | 2018-06-25 | 249831 | 16000 | 14400 | 340 | 580 | 148 | 225 | 20 | 9788971998557 | 8971998555 |
| 8 | 에로틱 조선 | 박영규 | 웅진지식하우스 | 2019-07-22 | 10173 | 18000 | 16200 | 322 | 554 | 145 | 215 | 30 | 9788901233024 | 8901233029 |
| 9 | 설민석의 무도 한국사 특강 | 설민석 | 휴먼큐브 | 2017-11-15 | 64470 | 22000 | 19800 | 436 | 915 | 170 | 240 | 26 | 9791196025892 | 1196025894 |
CSV 파일 확인하기
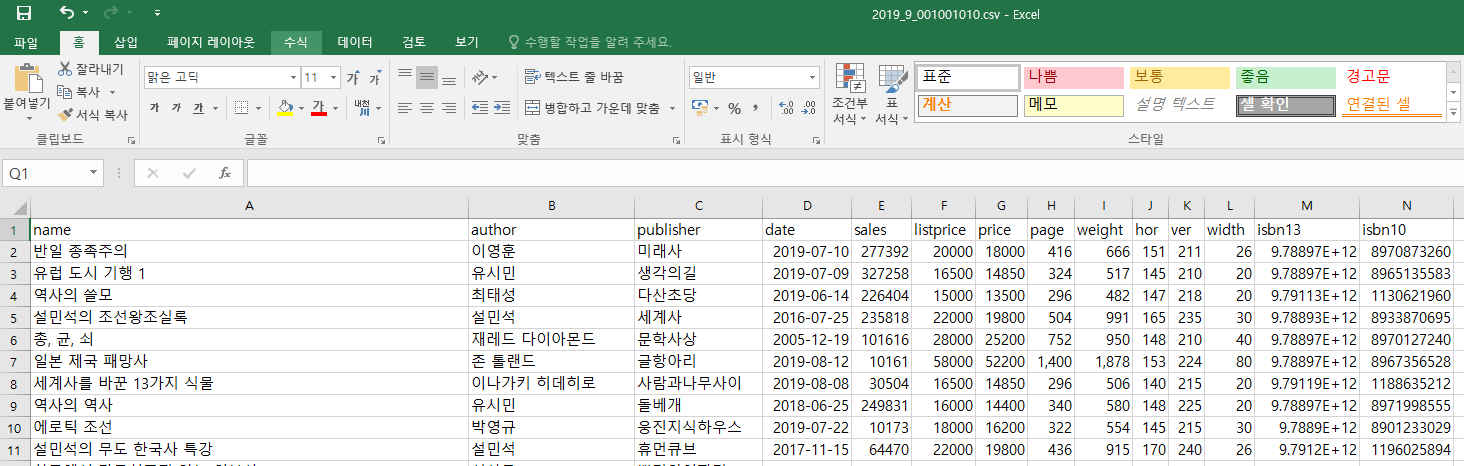
이상으로 파이썬을 이용한 YES24 데이터 수집 튜토리얼을 마치겠습니다.
yes24 크롤링 관련 글 목록
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 01
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 02
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 03
- 데이터 과학을 위한 파이썬 라이브러리 모음
댓글남기기