파이썬으로 데이터 자동으로 수집하기
안녕하세요! 이번 튜토리얼에서는 파이썬을 이용하여 웹 데이터를 자동으로 수집하고, 이를 데이터 분석을 위한 csv형태의 파일로 추출하는 과정에 대해 차근차근 설명해드리도록 하겠습니다. 인터넷 서점으로 유명한 YES24의 베스트셀러 도서의 이름, 저자명, 출간일, 판매가격, 무게 등의 데이터를 실제로 수집하는 방법을 예로 들어 보겠습니다.
yes24 크롤링 관련 글 목록
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 01
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 02
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 03
- 데이터 과학을 위한 파이썬 라이브러리 모음
크롤링할 웹 사이트 확인하기
먼저, 인터넷 서점 사이트인 YES24에 접속한 뒤, 메뉴의 ‘베스트셀러’ 탭을 클릭합니다. 여러 항목 중 ‘역사’ 장르의 월별 도서에 관한 데이터를 수집하도록 하겠습니다.
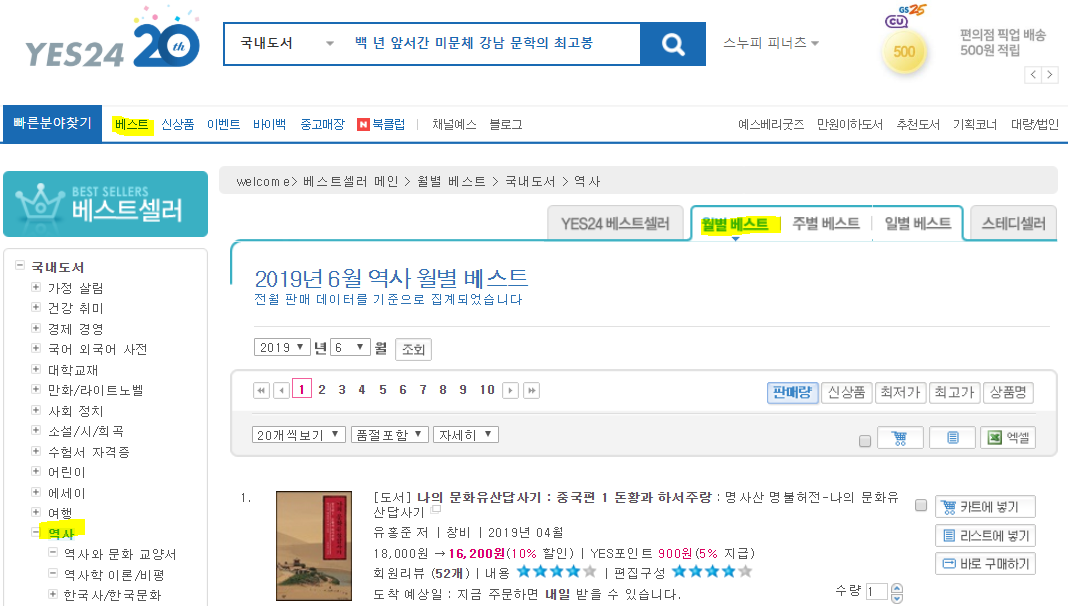
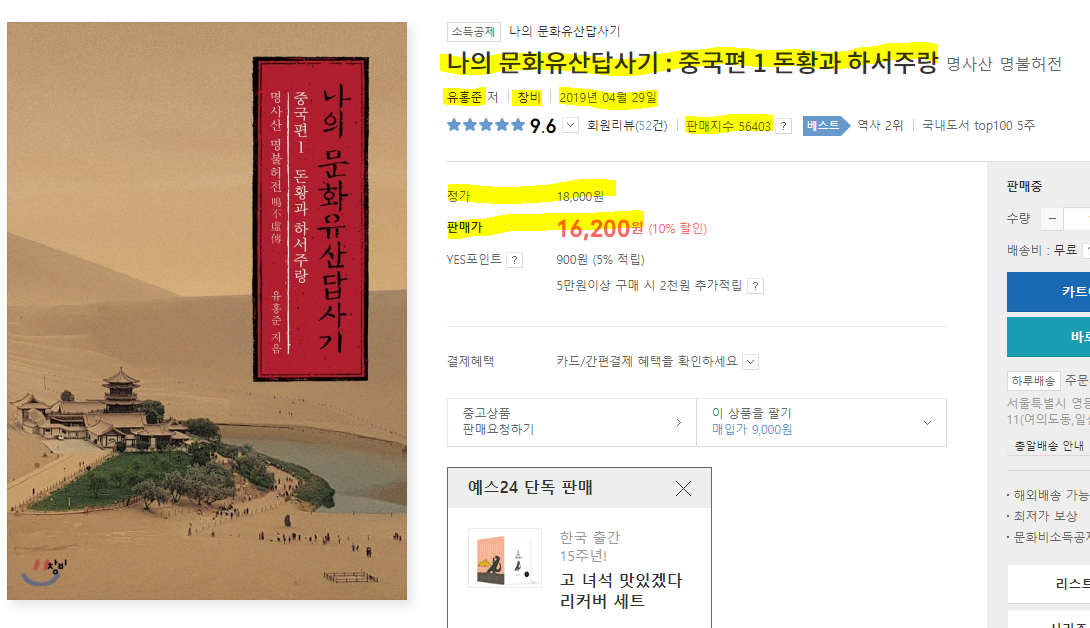
여러 도서 리스트 중 가장 상단에 있는 도서의 링크를 클릭합니다. ‘책 제목’, ‘저자 명’, ‘출판사 명’, ‘출간일’, ‘판매지수’, ‘정가’, 그리고 ‘판매가’ 등 수집하고자 하는 데이터의 위치를 다음과 같이 확인합니다.
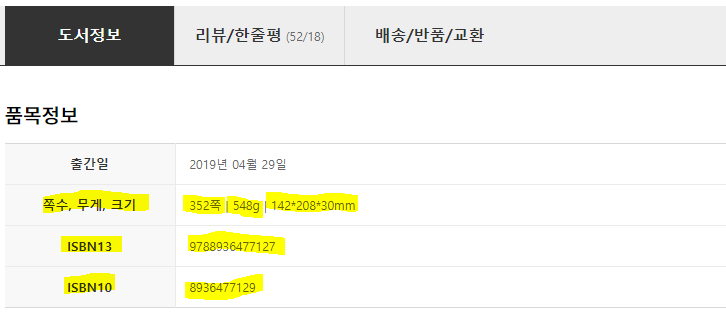
스크롤을 내려보면 아래와 같이 책의 ‘쪽수’, ‘무게’, ‘크기’, ‘ISBN13’, 그리고 ‘ISBN10’등의 추가 정보도 함께 크롤링해보겠습니다.
파이썬 라이브러리 Requests, BeautifulSoup4
파이썬 웹 크롤러를 만들기위해 requests와 BeautifulSoup4를 사용하겠습니다. 패키지가 설치되어 있지 않다면 아래와 같이 pip를 이용해 설치해줍니다.
numpy,pandas는 미리 설치되어있다고 가정하였습니다.
pip install requests
pip install beautifulsoup4
사용할 패키지 임포트하기
import numpy as np
import pandas as pd
import Requests
from bs4 import BeautifulSoup4
여기까지 따라오셨다면, 파이썬 웹 크롤러를 만들 준비가 모두 끝났습니다. 그럼 다음 포스팅에서 본격적으로 수집하고자하는 데이터의 주소를 참조하여 Pandas DataFrame 형식으로 수집해보겠습니다.
yes24 크롤링 관련 글 목록
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 01
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 02
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 03
- 데이터 과학을 위한 파이썬 라이브러리 모음
댓글남기기