Docker Compose를 사용하면 Apache Spark와 Apache Kafka를 간단하게 설치해 사용할 수 있습니다. docker-compose.yml 파일을 작성해 Spark를 사용할 수 있는 간단한 환경을 구축해보겠습니다. Spark와 Kafka 외에도 Jupyter Lab, Zeppelin 등의 컨테이너도 함께 실행해보겠습니다. 컨테이너 실행 후 Jupyter Lab에서 PySpark API를 통해 Kafka 토픽에 메시지를 저장하고 저장된 메시지를 읽는 과정을 테스트해보겠습니다.
docker-compose.yml 파일 작성하기
다음은 Apache Spark와 Apache Kafka를 포함하는 docker-compose.yml 파일의 예시입니다. 이 파일을 사용하여 여러 컨테이너를 동시에 설정하고 실행할 수 있습니다. 각 서비스 설정은 해당 서비스의 기능과 네트워크 설정을 정의합니다.
version: '3'
services:
spark-master:
image: bitnami/spark:latest
ports:
- "7070:8080"
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
spark-worker:
image: bitnami/spark:latest
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_MEMORY=2g
- SPARK_WORKER_CORES=2
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
depends_on:
- spark-master
jupyterlab:
image: jupyter/pyspark-notebook:latest
ports:
- "8888:8888"
volumes:
- ./jupyterlab:/home/jovyan/work
environment:
- JUPYTER_ENABLE_LAB=yes
- GRANT_SUDO=yes
depends_on:
- spark-master
user: "1000"
zeppelin:
image: apache/zeppelin:0.9.0
ports:
- "8081:8080"
volumes:
- ./zeppelin/notebook:/notebook
- ./zeppelin/logs:/logs
environment:
- ZEPPELIN_LOG_DIR=/logs
- ZEPPELIN_NOTEBOOK_DIR=/notebook
- ZEPPELIN_ADDR=0.0.0.0
- ZEPPELIN_PORT=8080
user: root
depends_on:
- spark-master
zookeeper:
image: bitnami/zookeeper:latest
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:latest
ports:
- "9092:9092"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092
- ALLOW_PLAINTEXT_LISTENER=yes
depends_on:
- zookeeper
컨테이너 설명
- spark-master: Spark 클러스터의 마스터 노드 역할을 합니다. 이 컨테이너는 다른 Spark 워커 노드들을 관리하고, 작업을 할당합니다.
- spark-worker: 실제 데이터 처리 작업을 수행하는 Spark 워커 노드입니다. 이 노드는 마스터 노드에 의해 할당된 작업을 수행하며, 설정에 따라 사용할 수 있는 메모리와 코어 수를 조정할 수 있습니다.
- jupyterlab: PySpark 코드를 작성하고 실행할 수 있는 Jupyter Lab 환경을 제공합니다. 이 환경을 통해 사용자는 브라우저에서 바로 Spark 작업을 개발하고 테스트할 수 있습니다.
- zeppelin: 데이터 분석과 시각화를 위한 Apache Zeppelin 노트북을 제공합니다. Spark와의 통합을 통해 대화형 데이터 탐색을 할 수 있습니다.
- zookeeper: Kafka 클러스터의 설정 정보를 관리하며, 클러스터 내 브로커들의 상태를 추적합니다.
- kafka: 메시지 브로커 역할을 수행하는 Apache Kafka 서비스입니다. 이 컨테이너는 데이터 스트리밍 처리를 위해 메시지를 수신하고 저장합니다.
Spark와 Kafka 컨테이너 실행하기
다음 명령으로 컨테이너들을 실행합니다.
sudo docker-compose up -d
웹 브라우저에서 확인하기
방화벽 공개 설정이 정상적으로 되어 있다면, 웹 브라우저에서 아래 URL에 접속하면 각 컨테이너의 UI를 확인할 수 있다.
- Apache Spark: http://Public IP:7070
- Apache Zeppelin: http://Public IP:8081
- Jupyterlab: http://Public IP:8888
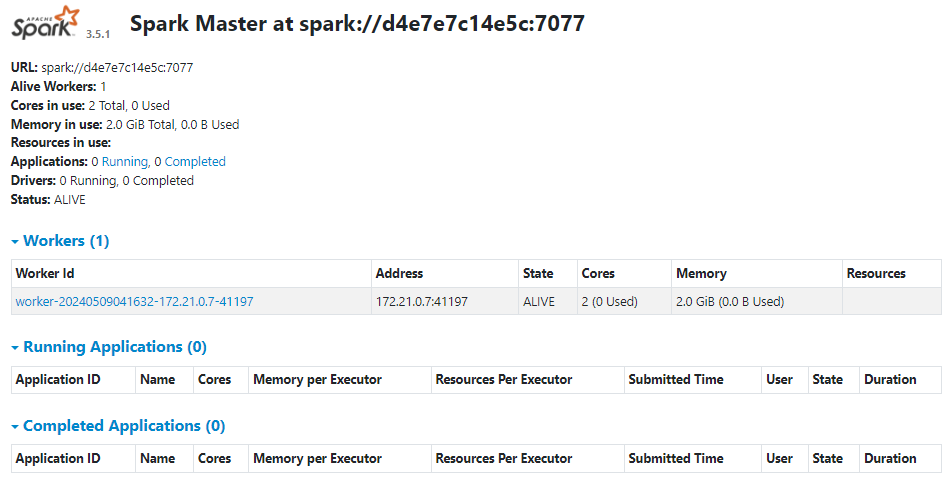
Spark 예시
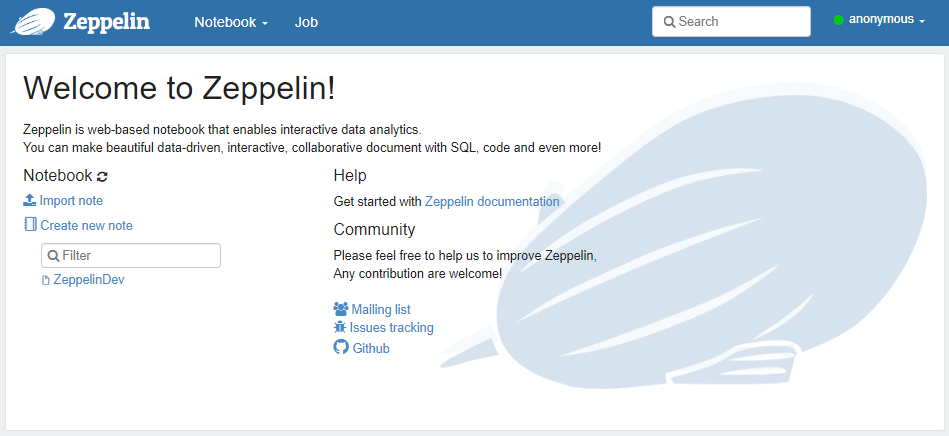
Zeppelin 예시
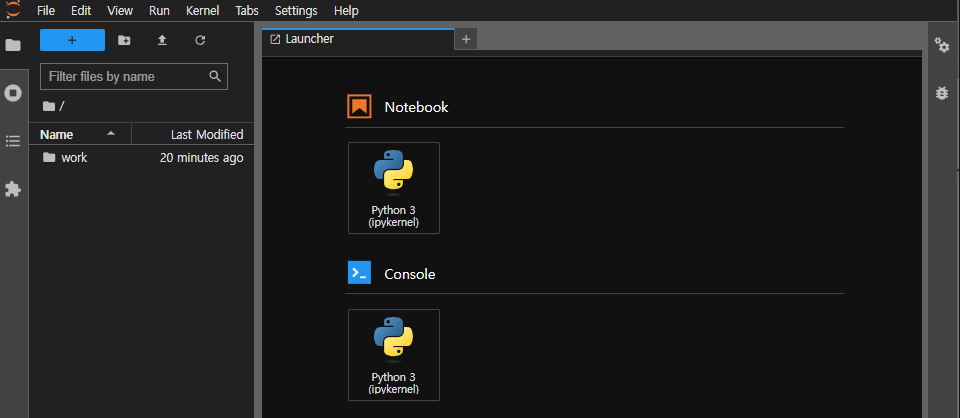
Jupyter Lab 예시
Jupyter Lab에서 PySpark 실행하기
Jupyter Lab 환경에서 PySpark를 활용하여 Kafka와 상호 작용하는 방법을 알아보겠습니다. Jupyter Lab은 데이터 사이언스 작업을 위한 훌륭한 도구로, 코드를 작성하고 결과를 실시간으로 볼 수 있는 인터랙티브한 환경을 제공합니다. 여기서는 PySpark 세션을 설정하고, Kafka에 메시지를 작성하고, 작성한 메시지를 읽는 전체 과정을 단계별로 살펴보겠습니다.
PySpark 세션 설정
PySpark 세션을 설정하는 것은 Spark 기능을 사용할 수 있게 해주는 첫 번째 단계입니다. 이 세션을 통해 Spark 클러스터에 접근하고, 데이터 처리 및 분석 작업을 수행할 수 있습니다.
from pyspark.sql import SparkSession
app_name = "PySpark Kafka Test"
conf_1 = "spark.jars.packages"
conf_2 = "org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1"
spark = SparkSession.builder.appName(app_name).config(conf_1, conf_2).getOrCreate()
Kafka로 메시지 작성
데이터를 Kafka로 보내는 과정을 구현합니다. 이 예시에서는 간단한 메시지를 생성하여 Kafka 토픽에 저장합니다. 이 작업을 통해 데이터 스트리밍 과정을 직관적으로 이해할 수 있습니다.
# Kafka에 데이터 프레임을 생성하여 데이터를 보냄
values = [("first message",), ("second message",), ("third message",)]
df = spark.createDataFrame(values, ["value"])
query = df \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka:9092") \
.option("topic", "test-topic") \
.save()
Kafka에서 메시지 읽기
이제 Kafka에서 데이터를 읽는 과정을 구현합니다. 이 부분에서는 Kafka 토픽에 저장된 메시지를 읽고, 결과를 출력합니다. 이를 통해 Kafka로부터 실시간 데이터 스트림을 처리하는 방법을 알 수 있습니다.
# Kafka로부터 데이터를 읽어 들임
df_read = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka:9092") \
.option("subscribe", "test-topic") \
.option("startingOffsets", "earliest") \
.load()
# 읽은 데이터를 문자열로 변환
df_read.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").show(truncate=False)
+----+--------------+
|key |value |
+----+--------------+
|NULL|first message |
|NULL|third message |
|NULL|second message|
+----+--------------+
이와 같은 과정을 통해 Jupyter Lab에서 PySpark를 사용하여 Kafka와의 데이터 스트리밍을 간편하게 수행할 수 있음을 알 수 있습니다. 이후에는 실시간 데이터를 처리하여 아파치 슈퍼셋을 통해 대시보드로 시각화하는 방법에 대해 다뤄보겠습니다. 감사합니다.
댓글남기기