책 한 권에 대한 데이터 수집하기
이전 포스팅 ‘파이썬을 이용한 YES24 데이터 크롤링 01‘에서 데이터를 수집할 웹 사이트에 접속하여 크롤링할 위치를 확인하고, 파이썬 라이브러리인 requests와 BeautifulSoup4 설치 방법에 대해 살펴봤습니다. 이번 파트에서는 간단한 파이썬 코드로 직접 데이터를 수집해보겠습니다.
yes24 크롤링 관련 글 목록
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 01
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 02
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 03
- 데이터 과학을 위한 파이썬 라이브러리 모음
크롤링할 데이터의 태그 위치 정보 가져오기
‘YES24 - 베스트셀러 - 역사 - 월별 베스트 - 2019년 06월’ 페이지에 접속합니다. 가장 상단에 노출된 도서 제목 링크를 클릭합니다.
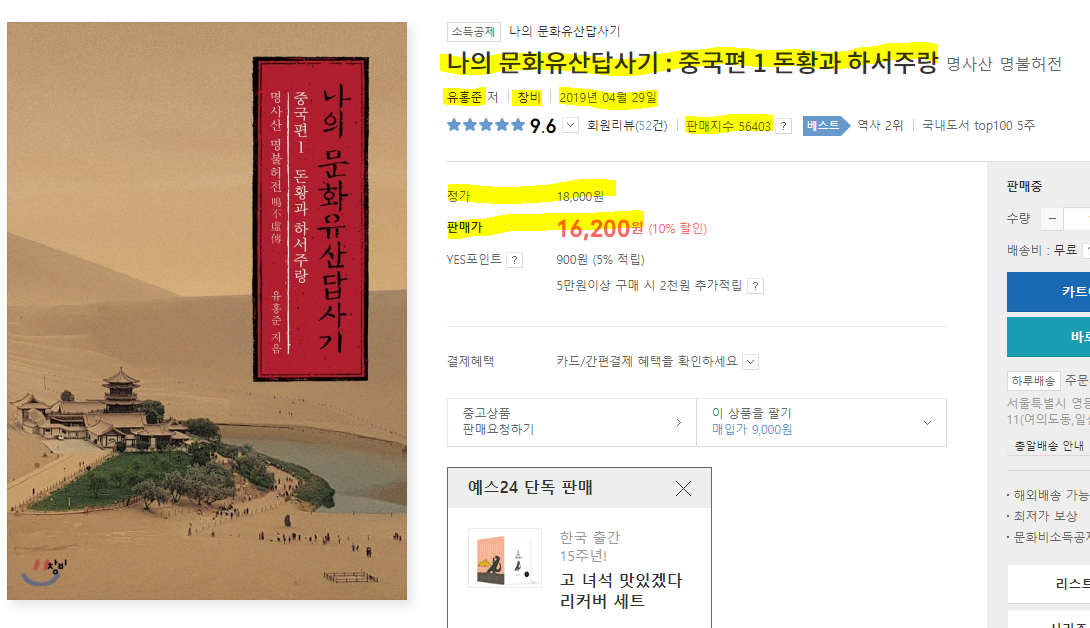
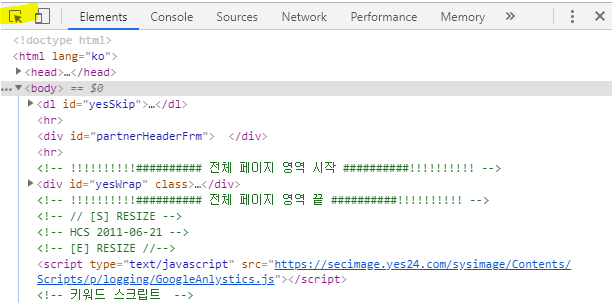
‘책 제목’, ‘저자 명’, ‘출판사 명’, ‘출간일’, ‘판매지수’, ‘정가’, 그리고 ‘판매가’ 데이터를 가져오기 위해 현재 웹 사이트의 HTML문서 안의 각 항목의 위치를 확인해보겠습니다. 크롬 웹 브라우저 기준으로 F12키를 눌러 크롬 개발자 도구를 열고, 좌측 상단의 ‘화살표’ 아이콘을 클릭합니다.
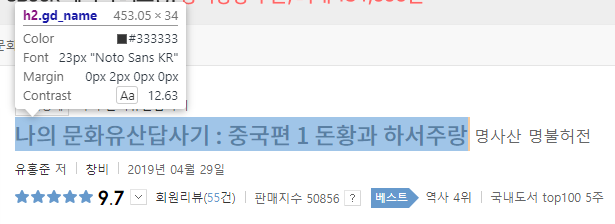
‘책 제목’ 부분으로 커서를 옮기고, 아래와 같이 블록 지정 상태가 되면 클릭을 해줍니다.
오른쪽 크롬 개발자 도구에 파랗게 블록 지정된 부분이 ‘책 제목’에 해당하는 태그의 위치입니다. 이 부분 위로 커서를 옮긴 후, 우클릭하여 ‘Copy’ - ‘Copy selector’ 를 선택합니다.
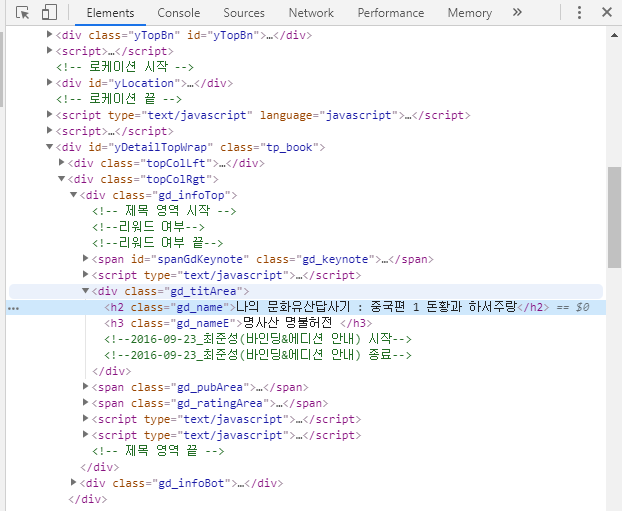
텍스트 편집기나 코드창에 붙여넣기를 하면 다음과 같이 태그의 위치 정보가 복사된 것을 확인할 수 있습니다.
#yDetailTopWrap > div.topColRgt > div.gd_infoTop > div > h2
같은 방법을 적용하여 원하는 데이터가 위치한 태그의 정보를 확인해보면 다음과 같습니다.
| 항목명 | 태그위치 |
|---|---|
| 책 제목 | #yDetailTopWrap > div.topColRgt > div.gd_infoTop > div > h2 |
| 저자 명 | #yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_auth > a |
| 출판사 명 | #yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_pub > a |
| 출간일 | #yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_pubArea > span.gd_date |
| 판매지수 | #yDetailTopWrap > div.topColRgt > div.gd_infoTop > span.gd_ratingArea > span.gd_sellNum |
| 정가 | #yDetailTopWrap > div.topColRgt > div.gd_infoBot > div.gd_infoTbArea > div:nth-child(3) > table > tbody > tr:nth-child(1) > td > span > em |
| 판매가 | #yDetailTopWrap > div.topColRgt > div.gd_infoBot > div.gd_infoTbArea > div:nth-child(3) > table > tbody > tr.accentRow > td > span > em |
파이썬 크롤러로 ‘책 제목’ 만 추출하기
파이썬 웹 크롤링을 위해 필요한 라이브러리들을 임포트해줍니다.
import numpy as np
import pandas as pd
import Requests
from bs4 import BeautifulSoup4
현재 활성화되어 있는 도서 페이지의 주소를 url 변수에 할당해줍니다. requests와 BeautifulSoup4 라이브러리의 다음 메소드들로 url에 해당하는 웹 사이트의 HTML 정보를 읽어옵니다. 이때, 위에서 찾은 책 제목에 해당하는 태그의 위치를 tag_name 변수에 할당하고, soup.select를 이용하여 해당 태그만 선택하여 가져옵니다.
url = 'http://www.yes24.com/Product/Goods/71933018'
res = requests.post(url)
soup = BeautifulSoup(res.text, 'html5lib')
tag_name = '#yDetailTopWrap > div.topColRgt > div.gd_infoTop > div > h2'
books = soup.select(tag_name)
print(books)
books변수의 값을 출력하면 다음과 같이 책 제목이 위치한 h2 태그를 출력해줍니다.
[<h2 class="gd_name">나의 문화유산답사기 : 중국편 1 돈황과 하서주랑</h2>]
books 리스트 안에 있는 태그의 텍스트만 추출하기 위해 text메소드를 적용하여 name 변수에 책의 제목 값을 할당합니다.
name = books[0].text
print(name)
name 출력 결과, 책 제목만 불러와진 것을 확인할 수 있습니다.
나의 문화유산답사기 : 중국편 1 돈황과 하서주랑
같은 방법을 활용해 나머지 데이터 가져오기
위에서 ‘책 제목’에 해당하는 데이터를 수집하는 것과 동일한 방법을 적용하면 ‘저자 명’, ‘출판사 명’, ‘출간일’, ‘판매지수’, ‘정가’, 그리고 ‘판매가’ 데이터를 가져올 수 있습니다. 그러나 특정 항목의 경우 페이지 마다 변칙이 있는 경우가 존재합니다. 따라서 다음 포스팅에서는 어떤 변칙이 존재하는지 실제로 확인해보고, 예외 처리를 하는 방법에 대해서 소개해드리겠습니다. 감사합니다!
yes24 크롤링 관련 글 목록
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 01
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 02
- 크롤링(Crawling) - YES24 베스트셀러 데이터 수집 03
- 데이터 과학을 위한 파이썬 라이브러리 모음
댓글남기기