FRED 데이터 조회하기
![]()
파이썬 PublicDataReader 라이브러리를 이용하면 FRED에서 제공하는 경제 데이터를 쉽게 조회할 수 있습니다.
PublicDataReader
PublicDataReader는 공공 데이터를 자동으로 조회할 수 있는 파이썬 라이브러리입니다. 이 라이브러리로 공공데이터포털과 국가통계포털(KOSIS)과 같이 오픈 API 서비스로 제공하는 공공 데이터를 쉽게 조회할 수 있습니다. 인증키가 필요한 공공 데이터는 인증키를 사용하여 조회할 수 있고, 인증키가 필요하지 않은 데이터는 별도의 인증 절차 없이 조회할 수 있습니다. PublicDataReader를 이용하면 일반적인 공공 데이터 조회 과정에서 필요한 API 명세 찾기, 요청 작성, 반환된 데이터 정리 과정을 자동으로 처리할 수 있고, 웹에 공개된 데이터를 조회할 때도 데이터 수집과 가공 과정을 자동화할 수 있습니다. 이를 통해 코드 작성이 간결해지고 공공 데이터 조회 작업이 편리해집니다.
FRED API 신청하기
FRED에서 제공하는 API 서비스를 이용하려면 인증키가 필요합니다. 인증키를 얻기 위해서는 FRED API에 회원가입 후 FRED API Key에서 간단한 신청서를 작성하면 됩니다.
시리즈 검색하기
FRED의 ‘시리즈’는 시간에 따른 특정 경제 지표의 변화를 나타내는 데이터 세트입니다. 이러한 시리즈는 일련의 연속적인 데이터 포인트를 포함하여 경제 지표의 시간 경과에 따른 변화를 표현합니다. 각 시리즈는 특정 경제 지표(예: 실업률, GDP, 인플레이션 등)를 대표하며, 이 데이터는 특정 기간(일, 월, 분기, 연도 등) 동안 수집됩니다. 이러한 시리즈는 경제적 패턴과 경향을 분석하고 이해하는 데 도움이 됩니다.
이와 같은 시리즈를 검색하려면 api.get_data() 메서드의 인자인 api_name에 series_search를 입력하고, search_text에 검색할 시리즈의 키워드를 입력하면 됩니다. 검색 결과에서 원하는 시리즈의 ID 값을 확인할 수 있습니다. 이 시리즈의 ID 값은 시리즈 데이터를 조회할 때 사용합니다. 예를 들어, 인플레이션과 관련된 지표인 소비자 가격 지수(consumer price index)의 시리즈 ID 값을 확인하려면 다음과 같이 search_text에 consumer price index라고 입력하면 됩니다.
search_text = "consumer price index"
result = api.get_data(
api_name="series_search",
search_text=search_text
)
result.head()
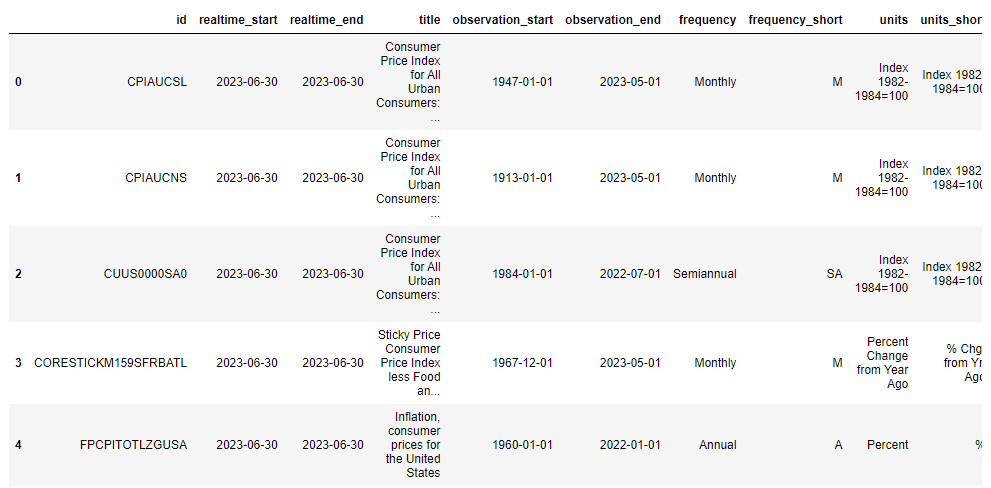
미국 소비자 물가 지수 CPI(Consumer Price Index)
- 시리즈명: Consumer Price Index for All Urban Consumers: All Items in U.S. City Average
- 시리즈명(번역): 모든 도시 소비자를 위한 소비자 물가 지수: 미국 도시 평균의 모든 품목
- 단위: 지수 1982-1984=100, 계절에 따라 조정되지 않음.
- 빈도: 월간
- FRED URL: https://fred.stlouisfed.org/series/CPIAUCNS
- 출처: 미국 노동 통계국(U.S. Bureau of Labor Statistics)
def CPI() -> pd.DataFrame:
"""CPI(Consumer Price Index) 시리즈 데이터 조회 함수"""
# 시리즈 ID 값
series_id = "CPIAUCNS"
# 시리즈 데이터 조회
df = api.get_data(
api_name="series_observations",
series_id=series_id
)
# value 컬럼 숫자형 변환
df['value'] = pd.to_numeric(df['value'], errors="coerce")
# date 컬럼 날짜형 변환
df['date'] = pd.to_datetime(df['date'])
# date 컬럼을 인덱스로 설정
df = df.set_index("date")
# 전년 동월 값 컬럼 생성
df['value_last_year'] = df['value'].shift(12)
df['CPI(YoY)'] = (df['value'] - df['value_last_year']) / df['value_last_year'] * 100
# 전년 동월 값 컬럼만 선택
df = df[['CPI(YoY)']]
return df
미국 개인 소비 지출 PCE(Personal Consumption Expenditures)
- 시리즈명: Personal Consumption Expenditures: Chain-type Price Index
- 시리즈명(번역): 개인 소비 지출: 체인형 물가지수
- 단위: 지수 2012=100, 계절에 따라 조정됨.
- 빈도: 월간
- FRED URL: https://fred.stlouisfed.org/series/PCEPI
- 출처: 미국 경제 분석국 (U.S. Bureau of Economic Analysis)
def PCE() -> pd.DataFrame:
"""PCE(Personal Consumption Expenditures) 시리즈 데이터 조회 함수"""
# 시리즈 ID 값
series_id = "PCEPI"
# 시리즈 데이터 조회
df = api.get_data(
api_name="series_observations",
series_id=series_id
)
# value 컬럼 숫자형 변환
df['value'] = pd.to_numeric(df['value'], errors="coerce")
# date 컬럼 날짜형 변환
df['date'] = pd.to_datetime(df['date'])
# date 컬럼을 인덱스로 설정
df = df.set_index("date")
# 전년 동월 값 컬럼 생성
df['value_last_year'] = df['value'].shift(12)
df['PCE(YoY)'] = (df['value'] - df['value_last_year']) / df['value_last_year'] * 100
# 전년 동월 값 컬럼만 선택
df = df[['PCE(YoY)']]
return df
미국 생산자 물가 지수 PPI(Producer Price Index)
- 시리즈명: Producer Price Index by Commodity: Final Demand
- 시리즈명(번역): 상품별 생산자 물가 지수: 최종 수요
- 단위: 지수 2009년 11월=100, 계절에 따라 조정되지 않음.
- 빈도: 월간
- FRED URL: https://fred.stlouisfed.org/series/PPIFID
- 출처: 미국 노동 통계국(Source: U.S. Bureau of Labor Statistics)
def PPI() -> pd.DataFrame:
"""PPI(Producer Price Index) 시리즈 데이터 조회 함수"""
# 시리즈 ID 값
series_id = "PPIFID"
# 시리즈 데이터 조회
df = api.get_data(
api_name="series_observations",
series_id=series_id
)
# value 컬럼 숫자형 변환
df['value'] = pd.to_numeric(df['value'], errors="coerce")
# date 컬럼 날짜형 변환
df['date'] = pd.to_datetime(df['date'])
# date 컬럼을 인덱스로 설정
df = df.set_index("date")
# 전년 동월 값 컬럼 생성
df['value_last_year'] = df['value'].shift(12)
df['PPI(YoY)'] = (df['value'] - df['value_last_year']) / df['value_last_year'] * 100
# 전년 동월 값 컬럼만 선택
df = df[['PPI(YoY)']]
return df
미국 연준 기준금리
- 시리즈명: Federal Funds Target Range - Upper Limit
- 시리즈명(번역): 연방 기금 목표 범위 - 상한
- 단위: 백분율, 계절에 따라 조정되지 않음.
- 빈도: 매일, 7일.
- FRED URL: https://fred.stlouisfed.org/series/DFEDTARU
- 출처: 미국 연방준비제도 이사회(Board of Governors of the Federal Reserve System (US))
def FED_RATE() -> pd.DataFrame:
"""목표 연준 기준금리 시리즈 데이터 조회 함수"""
# 시리즈 ID 값
series_id = "DFEDTARU"
# 시리즈 데이터 조회
df = api.get_data(
api_name="series_observations",
series_id=series_id
)
# value 컬럼 숫자형 변환 컬럼 생성
df['FED RATE'] = pd.to_numeric(df['value'], errors="coerce")
# date 컬럼 날짜형 변환
df['date'] = pd.to_datetime(df['date'])
# date 컬럼을 인덱스로 설정
df = df.set_index('date')
# 기준금리 컬럼만 선택
df = df[['FED RATE']]
return df
케이스-쉴러 미국 주택 가격 지수 Case-Shiller U.S. Home Price Index
- 시리즈명: S&P/Case-Shiller U.S. National Home Price Index
- 시리즈명(번역): S&P/케이스-실러 미국 전국 주택 가격 지수
- 단위: 지수 1월 2000=100, 계절에 따라 조정됨.
- 빈도: 월간
- FRED URL: https://fred.stlouisfed.org/series/CSUSHPISA
- 출처: S&P 다우존스 인덱스 LLC(S&P Dow Jones Indices LLC)
def CS() -> pd.DataFrame:
"""케이스-쉴러 전국 주택 가격 지수(미국) 시리즈 데이터 조회 함수"""
# 시리즈 ID 값
series_id = "CSUSHPISA"
# 시리즈 데이터 조회
df = api.get_data(
api_name="series_observations",
series_id=series_id
)
# value 컬럼 숫자형 변환
df['value'] = pd.to_numeric(df['value'], errors="coerce")
# date 컬럼 날짜형 변환
df['date'] = pd.to_datetime(df['date'])
# date 컬럼을 인덱스로 설정
df = df.set_index("date")
# 전년 동월 값 컬럼 생성
df['value_last_year'] = df['value'].shift(12)
df['CS(YoY)'] = (df['value'] - df['value_last_year']) / df['value_last_year'] * 100
# 전년 동월 값 컬럼만 선택
df = df[['CS(YoY)']]
return df
미국 경제 성장률(직전 분기 대비 GDP 성장률(연율))
- 시리즈명: Real Gross Domestic Product
- 시리즈명(번역): 실질 국내 총생산
- 단위: 이전 기간 대비 변화율, 계절 조정 연간 비율
- 빈도: 분기별
- FRED URL: https://fred.stlouisfed.org/series/A191RL1Q225SBEA
- 출처: 미국 경제 분석국(Source: U.S. Bureau of Economic Analysis)
def GDP() -> pd.DataFrame:
"""미국 GDP 성장률(전분기 대비 연율) 시리즈 데이터 조회 함수"""
# 시리즈 ID 값
series_id = "A191RL1Q225SBEA"
# 시리즈 데이터 조회
df = api.get_data(
api_name="series_observations",
series_id=series_id
)
# value 컬럼 숫자형 변환
df['GDP RATE'] = pd.to_numeric(df['value'], errors="coerce")
# date 컬럼 날짜형 변환
df['date'] = pd.to_datetime(df['date'])
# date 컬럼을 인덱스로 설정
df = df.set_index("date")
# GDP 성장률 컬럼만 선택
df = df[['GDP RATE']]
return df
데이터 조회하기
cpi = CPI()
pce = PCE()
ppi = PPI()
fed_rate = FED_RATE()
cs = CS()
gdp = GDP()
데이터 병합하기
# 데이터 병합
dfs = [cpi, pce, ppi, fed_rate, cs, gdp]
# 날짜 기준을 일별로 변환 후 결측값은 이전 값으로 대체
dfs = list(map(lambda x: x.resample("D").asfreq().ffill(), dfs))
# 데이터 병합
df = pd.concat(dfs, axis=1).ffill()
# 기간 설정
start_date = "2019-01-01"
target = df[start_date:]
target.tail()
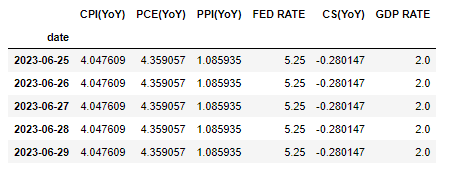
plotly로 데이터 시각화하기
import plotly.express as px
fig = px.line(target, x=target.index, y=list(target.columns))
fig.update_layout(
title={
'text': "글로벌 주요 경제 지표",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
xaxis_title="날짜",
yaxis_title="값",
)
fig.show()
댓글남기기