제1장 : R 기초와 데이터 마트
먼저 데이터 분석을 수행할 환경의 경로를 설정합니다.
setwd('C:/Users/wooil/Documents/GitHub/ADP')
getwd()
‘C:/Users/wooil/Documents/GitHub/ADP’
제2절 데이터 마트
-
어떤 모델링 기법을 사용하든지 모델 개발을 위해 데이터를 미리 시스템에 체계적으로 준비해 놓으면 모델링이 수월해짐.
-
어떤 모델링 도구는 데이터베이스에서 직접 값을 가져다 변형할 수 있는 기능도 제공함. 따라서 모델링을 진행하기 전에 데이터를 수집, 변형하는 과정이 필요함.
-
잘 정리된 데이터 마트를 개발해 놓으면 보다 효율적이고 신속한 모델링이 될 수 있음.
-
데이터 마트란 데이터의 한 부분으로서 특정 사용자가 관심을 갖는 데이터들을 담은 비교적 작은 규모의 데이터 웨어하우스임. 즉, 일반적인 데이터베이스 형태로 갖고 있는 다양한 정보를 사용자의 요구 항목에 따라 체계적으로 분석하여 기업의 경영 활동을 돕기 위한 시스템을 말함.
-
데이터 웨어하우스는 정부 기관 또는 정부 전체의 상세 데이터를 포함하는데 비해, 데이터 마트는 전체적인 데이터 웨어하우스에 있는 일부 데이터를 가지고 특정 사용자를 대상으로 함.
-
데이터 웨어하우스와 데이터 마트의 구분은 사용자의 기능 및 제공 범위를 기준으로 함.
1. R reshape를 활용한 데이터 마트 개발
# 'reshape' 패키지
# melt, cast만을 사용하여 데이터를 재구성하거나 밀집화된 데이터를 유연하게 생성해줌
# 설치 및 불러오기
install.packages("reshape")
library(reshape)
Installing package into 'C:/Users/wooil/Documents/R/win-library/3.6'
(as 'lib' is unspecified)
package 'reshape' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\wooil\AppData\Local\Temp\Rtmpg7GsWG\downloaded_packages
샘플 데이터 불러오기
df = airquality
print(head(df, 10)) # 상위 10개 데이터 출력
print(names(df)) # 컬럼명 출력
names(df) = tolower(names(df)) # 컬럼명 소문자로 변경
print(names(df))
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10
[1] "Ozone" "Solar.R" "Wind" "Temp" "Month" "Day"
[1] "ozone" "solar.r" "wind" "temp" "month" "day"
melt 이용하여 id에 있는 변수를 기준으로 나머지 각 변수를 variable 데이터로 생성
이후 연산을 위해 결측값(missing values)을 제거하는 옵션인 na.rm을 TRUE로 설정
aqm = melt(df, id=c("month", "day"), na.rm=TRUE)
print(head(aqm))
month day variable value
1 5 1 ozone 41
2 5 2 ozone 36
3 5 3 ozone 12
4 5 4 ozone 18
5 5 6 ozone 28
6 5 7 ozone 23
cast 이용하여 엑셀의 피벗팅을 하듯이 자료를 변환함.
melt된 aqm을 이용해 “~”를 y, x축의 dimension과 measure에 해당되는 변수(variable) 값을 표시함.
참고) 엑셀의 피벗은 count할 때 distinct count 안 됨.
a <- cast(aqm, day ~ month ~ variable)
print(a)
, , variable = ozone
month
day 5 6 7 8 9
1 41 NA 135 39 96
2 36 NA 49 9 78
3 12 NA 32 16 73
4 18 NA NA 78 91
5 NA NA 64 35 47
6 28 NA 40 66 32
7 23 29 77 122 20
8 19 NA 97 89 23
9 8 71 97 110 21
10 NA 39 85 NA 24
11 7 NA NA NA 44
12 16 NA 10 44 21
13 11 23 27 28 28
14 14 NA NA 65 9
15 18 NA 7 NA 13
16 14 21 48 22 46
17 34 37 35 59 18
18 6 20 61 23 13
19 30 12 79 31 24
20 11 13 63 44 16
21 1 NA 16 21 13
22 11 NA NA 9 23
23 4 NA NA NA 36
24 32 NA 80 45 7
25 NA NA 108 168 14
26 NA NA 20 73 30
27 NA NA 52 NA NA
28 23 NA 82 76 14
29 45 NA 50 118 18
30 115 NA 64 84 20
31 37 NA 59 85 NA
, , variable = solar.r
month
day 5 6 7 8 9
1 190 286 269 83 167
2 118 287 248 24 197
3 149 242 236 77 183
4 313 186 101 NA 189
5 NA 220 175 NA 95
6 NA 264 314 NA 92
7 299 127 276 255 252
8 99 273 267 229 220
9 19 291 272 207 230
10 194 323 175 222 259
11 NA 259 139 137 236
12 256 250 264 192 259
13 290 148 175 273 238
14 274 332 291 157 24
15 65 322 48 64 112
16 334 191 260 71 237
17 307 284 274 51 224
18 78 37 285 115 27
19 322 120 187 244 238
20 44 137 220 190 201
21 8 150 7 259 238
22 320 59 258 36 14
23 25 91 295 255 139
24 92 250 294 212 49
25 66 135 223 238 20
26 266 127 81 215 193
27 NA 47 82 153 145
28 13 98 213 203 191
29 252 31 275 225 131
30 223 138 253 237 223
31 279 NA 254 188 NA
, , variable = wind
month
day 5 6 7 8 9
1 7.4 8.6 4.1 6.9 6.9
2 8.0 9.7 9.2 13.8 5.1
3 12.6 16.1 9.2 7.4 2.8
4 11.5 9.2 10.9 6.9 4.6
5 14.3 8.6 4.6 7.4 7.4
6 14.9 14.3 10.9 4.6 15.5
7 8.6 9.7 5.1 4.0 10.9
8 13.8 6.9 6.3 10.3 10.3
9 20.1 13.8 5.7 8.0 10.9
10 8.6 11.5 7.4 8.6 9.7
11 6.9 10.9 8.6 11.5 14.9
12 9.7 9.2 14.3 11.5 15.5
13 9.2 8.0 14.9 11.5 6.3
14 10.9 13.8 14.9 9.7 10.9
15 13.2 11.5 14.3 11.5 11.5
16 11.5 14.9 6.9 10.3 6.9
17 12.0 20.7 10.3 6.3 13.8
18 18.4 9.2 6.3 7.4 10.3
19 11.5 11.5 5.1 10.9 10.3
20 9.7 10.3 11.5 10.3 8.0
21 9.7 6.3 6.9 15.5 12.6
22 16.6 1.7 9.7 14.3 9.2
23 9.7 4.6 11.5 12.6 10.3
24 12.0 6.3 8.6 9.7 10.3
25 16.6 8.0 8.0 3.4 16.6
26 14.9 8.0 8.6 8.0 6.9
27 8.0 10.3 12.0 5.7 13.2
28 12.0 11.5 7.4 9.7 14.3
29 14.9 14.9 7.4 2.3 8.0
30 5.7 8.0 7.4 6.3 11.5
31 7.4 NA 9.2 6.3 NA
, , variable = temp
month
day 5 6 7 8 9
1 67 78 84 81 91
2 72 74 85 81 92
3 74 67 81 82 93
4 62 84 84 86 93
5 56 85 83 85 87
6 66 79 83 87 84
7 65 82 88 89 80
8 59 87 92 90 78
9 61 90 92 90 75
10 69 87 89 92 73
11 74 93 82 86 81
12 69 92 73 86 76
13 66 82 81 82 77
14 68 80 91 80 71
15 58 79 80 79 71
16 64 77 81 77 78
17 66 72 82 79 67
18 57 65 84 76 76
19 68 73 87 78 68
20 62 76 85 78 82
21 59 77 74 77 64
22 73 76 81 72 71
23 61 76 82 75 81
24 61 76 86 79 69
25 57 75 85 81 63
26 58 78 82 86 70
27 57 73 86 88 77
28 67 80 88 97 75
29 81 77 86 94 76
30 79 83 83 96 68
31 76 NA 81 94 NA
y축은 month, x축은 variable인데 “,”로 구분한 다음, mean 함수 적용함.
월별 각 변수들의 평균값 산출
b <- cast(aqm, month ~ variable, mean)
print(b)
month ozone solar.r wind temp
1 5 23.61538 181.2963 11.622581 65.54839
2 6 29.44444 190.1667 10.266667 79.10000
3 7 59.11538 216.4839 8.941935 83.90323
4 8 59.96154 171.8571 8.793548 83.96774
5 9 31.44828 167.4333 10.180000 76.90000
y축은 month이지만 모든 변수에 대해 평균을 구하고 “|”를 이용해 산출물을 분리해 표시함.
조회용으로는 적합하나 데이터 마트를 만들기에는 좀 불편한 결과를 보여줌.
c <- cast(aqm, month ~. | variable, mean)
print(c)
$ozone
month (all)
1 5 23.61538
2 6 29.44444
3 7 59.11538
4 8 59.96154
5 9 31.44828
$solar.r
month (all)
1 5 181.2963
2 6 190.1667
3 7 216.4839
4 8 171.8571
5 9 167.4333
$wind
month (all)
1 5 11.622581
2 6 10.266667
3 7 8.941935
4 8 8.793548
5 9 10.180000
$temp
month (all)
1 5 65.54839
2 6 79.10000
3 7 83.90323
4 8 83.96774
5 9 76.90000
margin 옵션으로 행과 열에 대해 소계를 산출하는 기능임.
d <- cast(aqm, month ~ variable, mean, margins = c("grand_row", "grand_col"))
print(d)
month ozone solar.r wind temp (all)
1 5 23.61538 181.2963 11.622581 65.54839 68.70696
2 6 29.44444 190.1667 10.266667 79.10000 87.38384
3 7 59.11538 216.4839 8.941935 83.90323 93.49748
4 8 59.96154 171.8571 8.793548 83.96774 79.71207
5 9 31.44828 167.4333 10.180000 76.90000 71.82689
6 (all) 42.12931 185.9315 9.957516 77.88235 80.05722
모든 데이터를 처리하지 않고 특정 변수만 처리하고자 하는 경우
서브세트 기능을 이용해 아래 예제처럼 ozone에 대한 변수만 처리하도록 함.
e <- cast(aqm, day ~ month, subset=variable=="ozone")
print(e)
day 5 6 7 8 9
1 1 41 NA 135 39 96
2 2 36 NA 49 9 78
3 3 12 NA 32 16 73
4 4 18 NA NA 78 91
5 5 NA NA 64 35 47
6 6 28 NA 40 66 32
7 7 23 29 77 122 20
8 8 19 NA 97 89 23
9 9 8 71 97 110 21
10 10 NA 39 85 NA 24
11 11 7 NA NA NA 44
12 12 16 NA 10 44 21
13 13 11 23 27 28 28
14 14 14 NA NA 65 9
15 15 18 NA 7 NA 13
16 16 14 21 48 22 46
17 17 34 37 35 59 18
18 18 6 20 61 23 13
19 19 30 12 79 31 24
20 20 11 13 63 44 16
21 21 1 NA 16 21 13
22 22 11 NA NA 9 23
23 23 4 NA NA NA 36
24 24 32 NA 80 45 7
25 25 NA NA 108 168 14
26 26 NA NA 20 73 30
27 27 NA NA 52 NA NA
28 28 23 NA 82 76 14
29 29 45 NA 50 118 18
30 30 115 NA 64 84 20
31 31 37 NA 59 85 NA
min, max를 동시에 표시해주는 range는 min은 “_X1”, max는 “_X2”라는 suffix를 붙여줌.
f <- cast(aqm, month ~ variable, range)
print(f)
month ozone_X1 ozone_X2 solar.r_X1 solar.r_X2 wind_X1 wind_X2 temp_X1 temp_X2
1 5 1 115 8 334 5.7 20.1 56 81
2 6 12 71 31 332 1.7 20.7 65 93
3 7 7 135 7 314 4.1 14.9 73 92
4 8 9 168 24 273 2.3 15.5 72 97
5 9 7 96 14 259 2.8 16.6 63 93
2. sqldf를 이용한 데이터 분석
설치 및 불러오기
install.packages("sqldf")
library(sqldf)
Installing package into 'C:/Users/wooil/Documents/R/win-library/3.6'
(as 'lib' is unspecified)
also installing the dependencies 'ellipsis', 'rlang', 'zeallot', 'bit', 'vctrs', 'bit64', 'blob', 'memoise', 'gsubfn', 'proto', 'RSQLite', 'chron'
package 'ellipsis' successfully unpacked and MD5 sums checked
package 'rlang' successfully unpacked and MD5 sums checked
package 'zeallot' successfully unpacked and MD5 sums checked
package 'bit' successfully unpacked and MD5 sums checked
package 'vctrs' successfully unpacked and MD5 sums checked
package 'bit64' successfully unpacked and MD5 sums checked
package 'blob' successfully unpacked and MD5 sums checked
package 'memoise' successfully unpacked and MD5 sums checked
package 'gsubfn' successfully unpacked and MD5 sums checked
package 'proto' successfully unpacked and MD5 sums checked
package 'RSQLite' successfully unpacked and MD5 sums checked
package 'chron' successfully unpacked and MD5 sums checked
package 'sqldf' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\wooil\AppData\Local\Temp\Rtmpg7GsWG\downloaded_packages
Loading required package: gsubfn
Loading required package: proto
Loading required package: RSQLite
샘플 데이터 불러오기
df = iris
데이터 조회
print(sqldf("select * from df"))
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
11 5.4 3.7 1.5 0.2 setosa
12 4.8 3.4 1.6 0.2 setosa
13 4.8 3.0 1.4 0.1 setosa
14 4.3 3.0 1.1 0.1 setosa
15 5.8 4.0 1.2 0.2 setosa
16 5.7 4.4 1.5 0.4 setosa
17 5.4 3.9 1.3 0.4 setosa
18 5.1 3.5 1.4 0.3 setosa
19 5.7 3.8 1.7 0.3 setosa
20 5.1 3.8 1.5 0.3 setosa
21 5.4 3.4 1.7 0.2 setosa
22 5.1 3.7 1.5 0.4 setosa
23 4.6 3.6 1.0 0.2 setosa
24 5.1 3.3 1.7 0.5 setosa
25 4.8 3.4 1.9 0.2 setosa
26 5.0 3.0 1.6 0.2 setosa
27 5.0 3.4 1.6 0.4 setosa
28 5.2 3.5 1.5 0.2 setosa
29 5.2 3.4 1.4 0.2 setosa
30 4.7 3.2 1.6 0.2 setosa
31 4.8 3.1 1.6 0.2 setosa
32 5.4 3.4 1.5 0.4 setosa
33 5.2 4.1 1.5 0.1 setosa
34 5.5 4.2 1.4 0.2 setosa
35 4.9 3.1 1.5 0.2 setosa
36 5.0 3.2 1.2 0.2 setosa
37 5.5 3.5 1.3 0.2 setosa
38 4.9 3.6 1.4 0.1 setosa
39 4.4 3.0 1.3 0.2 setosa
40 5.1 3.4 1.5 0.2 setosa
41 5.0 3.5 1.3 0.3 setosa
42 4.5 2.3 1.3 0.3 setosa
43 4.4 3.2 1.3 0.2 setosa
44 5.0 3.5 1.6 0.6 setosa
45 5.1 3.8 1.9 0.4 setosa
46 4.8 3.0 1.4 0.3 setosa
47 5.1 3.8 1.6 0.2 setosa
48 4.6 3.2 1.4 0.2 setosa
49 5.3 3.7 1.5 0.2 setosa
50 5.0 3.3 1.4 0.2 setosa
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
54 5.5 2.3 4.0 1.3 versicolor
55 6.5 2.8 4.6 1.5 versicolor
56 5.7 2.8 4.5 1.3 versicolor
57 6.3 3.3 4.7 1.6 versicolor
58 4.9 2.4 3.3 1.0 versicolor
59 6.6 2.9 4.6 1.3 versicolor
60 5.2 2.7 3.9 1.4 versicolor
61 5.0 2.0 3.5 1.0 versicolor
62 5.9 3.0 4.2 1.5 versicolor
63 6.0 2.2 4.0 1.0 versicolor
64 6.1 2.9 4.7 1.4 versicolor
65 5.6 2.9 3.6 1.3 versicolor
66 6.7 3.1 4.4 1.4 versicolor
67 5.6 3.0 4.5 1.5 versicolor
68 5.8 2.7 4.1 1.0 versicolor
69 6.2 2.2 4.5 1.5 versicolor
70 5.6 2.5 3.9 1.1 versicolor
71 5.9 3.2 4.8 1.8 versicolor
72 6.1 2.8 4.0 1.3 versicolor
73 6.3 2.5 4.9 1.5 versicolor
74 6.1 2.8 4.7 1.2 versicolor
75 6.4 2.9 4.3 1.3 versicolor
76 6.6 3.0 4.4 1.4 versicolor
77 6.8 2.8 4.8 1.4 versicolor
78 6.7 3.0 5.0 1.7 versicolor
79 6.0 2.9 4.5 1.5 versicolor
80 5.7 2.6 3.5 1.0 versicolor
81 5.5 2.4 3.8 1.1 versicolor
82 5.5 2.4 3.7 1.0 versicolor
83 5.8 2.7 3.9 1.2 versicolor
84 6.0 2.7 5.1 1.6 versicolor
85 5.4 3.0 4.5 1.5 versicolor
86 6.0 3.4 4.5 1.6 versicolor
87 6.7 3.1 4.7 1.5 versicolor
88 6.3 2.3 4.4 1.3 versicolor
89 5.6 3.0 4.1 1.3 versicolor
90 5.5 2.5 4.0 1.3 versicolor
91 5.5 2.6 4.4 1.2 versicolor
92 6.1 3.0 4.6 1.4 versicolor
93 5.8 2.6 4.0 1.2 versicolor
94 5.0 2.3 3.3 1.0 versicolor
95 5.6 2.7 4.2 1.3 versicolor
96 5.7 3.0 4.2 1.2 versicolor
97 5.7 2.9 4.2 1.3 versicolor
98 6.2 2.9 4.3 1.3 versicolor
99 5.1 2.5 3.0 1.1 versicolor
100 5.7 2.8 4.1 1.3 versicolor
101 6.3 3.3 6.0 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica
103 7.1 3.0 5.9 2.1 virginica
104 6.3 2.9 5.6 1.8 virginica
105 6.5 3.0 5.8 2.2 virginica
106 7.6 3.0 6.6 2.1 virginica
107 4.9 2.5 4.5 1.7 virginica
108 7.3 2.9 6.3 1.8 virginica
109 6.7 2.5 5.8 1.8 virginica
110 7.2 3.6 6.1 2.5 virginica
111 6.5 3.2 5.1 2.0 virginica
112 6.4 2.7 5.3 1.9 virginica
113 6.8 3.0 5.5 2.1 virginica
114 5.7 2.5 5.0 2.0 virginica
115 5.8 2.8 5.1 2.4 virginica
116 6.4 3.2 5.3 2.3 virginica
117 6.5 3.0 5.5 1.8 virginica
118 7.7 3.8 6.7 2.2 virginica
119 7.7 2.6 6.9 2.3 virginica
120 6.0 2.2 5.0 1.5 virginica
121 6.9 3.2 5.7 2.3 virginica
122 5.6 2.8 4.9 2.0 virginica
123 7.7 2.8 6.7 2.0 virginica
124 6.3 2.7 4.9 1.8 virginica
125 6.7 3.3 5.7 2.1 virginica
126 7.2 3.2 6.0 1.8 virginica
127 6.2 2.8 4.8 1.8 virginica
128 6.1 3.0 4.9 1.8 virginica
129 6.4 2.8 5.6 2.1 virginica
130 7.2 3.0 5.8 1.6 virginica
131 7.4 2.8 6.1 1.9 virginica
132 7.9 3.8 6.4 2.0 virginica
133 6.4 2.8 5.6 2.2 virginica
134 6.3 2.8 5.1 1.5 virginica
135 6.1 2.6 5.6 1.4 virginica
136 7.7 3.0 6.1 2.3 virginica
137 6.3 3.4 5.6 2.4 virginica
138 6.4 3.1 5.5 1.8 virginica
139 6.0 3.0 4.8 1.8 virginica
140 6.9 3.1 5.4 2.1 virginica
141 6.7 3.1 5.6 2.4 virginica
142 6.9 3.1 5.1 2.3 virginica
143 5.8 2.7 5.1 1.9 virginica
144 6.8 3.2 5.9 2.3 virginica
145 6.7 3.3 5.7 2.5 virginica
146 6.7 3.0 5.2 2.3 virginica
147 6.3 2.5 5.0 1.9 virginica
148 6.5 3.0 5.2 2.0 virginica
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
print(sqldf("select * from df limit 10"))
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
print(sqldf("select count(*) from df where Species like 'se%'"))
count(*)
1 50
print(sqldf("select count(*) from df where Species like 've%'"))
count(*)
1 50
print(sqldf("select count(*) from df where Species like 'vi%'"))
count(*)
1 50
print(unique(df$Species))
[1] setosa versicolor virginica
Levels: setosa versicolor virginica
print(length(df$Species))
[1] 150
3. plyr
ply() 함수는 앞에 두 개의 문자를 접두사로 가짐.
첫 번째 문자는 입력하는 데이터 형태를 나타내고,
두 번째 문자는 출력하는 데이터 형태를 나타냄.
- d = 데이터 프레임 (data.frame)
- a = 배열 (array)
- l = 리스트 (list)
set.seed(1) # 랜덤시드 값 설정
d = data.frame(year = rep(2012:2014, each = 6), count=round(runif(9, 0, 20))) # runif(a, b, c) : b~c까지 정수 중 a개 랜덤추출
print(d)
year count
1 2012 5
2 2012 7
3 2012 11
4 2012 18
5 2012 4
6 2012 18
7 2013 19
8 2013 13
9 2013 13
10 2013 5
11 2013 7
12 2013 11
13 2014 18
14 2014 4
15 2014 18
16 2014 19
17 2014 13
18 2014 13
# plyr 패키지 불러오기
library(plyr)
Attaching package: 'plyr'
The following objects are masked from 'package:reshape':
rename, round_any
# cv(coefficient of variation, 변동계수) 구하는 기능 구현
cv = ddply(d, "year", function(x) {
mean.count = mean(x$count)
sd.count = sd(x$count)
cv = sd.count/mean.count
data.frame(cv.count = cv)
})
print(cv)
year cv.count
1 2012 0.5985621
2 2013 0.4382254
3 2014 0.3978489
transform, summarise를 동시에 사용하는 경우
summarise 옵션 : count 변수에 명령된 평균, 합 등 계산하고 새로 생긴 변수만 출력
transform 옵션 : 계산에 사용된 변수도 출력
a = ddply(d, "year", summarise, mean.count = mean(count))
print(a)
year mean.count
1 2012 10.50000
2 2013 11.33333
3 2014 14.16667
b = ddply(d, "year", transform, total.count = mean(count))
print(b)
year count total.count
1 2012 5 10.50000
2 2012 7 10.50000
3 2012 11 10.50000
4 2012 18 10.50000
5 2012 4 10.50000
6 2012 18 10.50000
7 2013 19 11.33333
8 2013 13 11.33333
9 2013 13 11.33333
10 2013 5 11.33333
11 2013 7 11.33333
12 2013 11 11.33333
13 2014 18 14.16667
14 2014 4 14.16667
15 2014 18 14.16667
16 2014 19 14.16667
17 2014 13 14.16667
18 2014 13 14.16667
4. 데이터 테이블
데이터 테이블(data.table)은 데이터 프레임과 유사하지만 보다 빠른 그룹화(grouping)와 순서화(ordering), 짧은 문장 지원 측면에서 데이터 프레임보다 매력적임.
‘data.table’ 패키지 설치 및 불러오기
install.packages("data.table")
library(data.table)
Installing package into 'C:/Users/wooil/Documents/R/win-library/3.6'
(as 'lib' is unspecified)
package 'data.table' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\wooil\AppData\Local\Temp\Rtmpg7GsWG\downloaded_packages
Attaching package: 'data.table'
The following object is masked from 'package:reshape':
melt
data.table 이용하여 데이터 프레임 생성
데이터 프레임과 다른 점 : 행 번호가 콜론(:)으로 출력되어 있어 첫 번째 열과 눈으로 쉽게 분리해서 볼 수 있음
DT = data.table(x=c("b","b","b","a","a"), v=rnorm(5)) # rnorm(n) : 정규분포에서 n개 난수 생성
print(DT)
x v
1: b 0.7635935
2: b -0.7990092
3: b -1.1476570
4: a -0.2894616
5: a -0.2992151
내장 데이터 불러오기
print(head(cars))
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
6 9 10
데이터 테이블 변환
CARS = data.table(cars)
print(head(CARS))
speed dist
1: 4 2
2: 4 10
3: 7 4
4: 7 22
5: 8 16
6: 9 10
데이터 테이블과 데이터 프레임의 차이 확인 : tables() 기능 이용해 크기, key, 용량 확인
tables()
print(sapply(CARS, class))
NAME NROW NCOL MB COLS KEY
1: CARS 50 2 0 speed,dist
2: DT 5 2 0 x,v
Total: 0MB
speed dist
"numeric" "numeric"
print(DT)
print(DT[4,])
print(setkey(DT, x))
print(DT)
tables()
x v
1: a -0.2894616
2: a -0.2992151
3: b 0.7635935
4: b -0.7990092
5: b -1.1476570
x v
1: b -0.7990092
x v
1: a -0.2894616
2: a -0.2992151
3: b 0.7635935
4: b -0.7990092
5: b -1.1476570
x v
1: a -0.2894616
2: a -0.2992151
3: b 0.7635935
4: b -0.7990092
5: b -1.1476570
NAME NROW NCOL MB COLS KEY
1: CARS 50 2 0 speed,dist
2: DT 5 2 0 x,v x
Total: 0MB
print(DT["b",]) # 'b' 가 들어간 모든 데이터 표시
print(DT["b", mult="first"]) # 'b' 가 들어간 모든 데이터 중 첫 번째 결과 표시
print(DT["b", mult="last"]) # 'b' 가 들어간 모든 데이터 중 마지막 결과 표시
x v
1: b 0.7635935
2: b -0.7990092
3: b -1.1476570
x v
1: b 0.7635935
x v
1: b -1.147657
제3절 결측값 처리와 이상값 검색
1. 데이터 탐색
# 데이터 기초 통계
iris=iris
print(head(iris))
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
str(iris)
summary(iris)
print(cov(iris[,1:4]))
print(cor(iris[,1:4]))
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 0.6856935 -0.0424340 1.2743154 0.5162707
Sepal.Width -0.0424340 0.1899794 -0.3296564 -0.1216394
Petal.Length 1.2743154 -0.3296564 3.1162779 1.2956094
Petal.Width 0.5162707 -0.1216394 1.2956094 0.5810063
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411
Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259
Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654
Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
2. 결측값 처리
y = c(1,2,3,NA)
print(y)
print(is.na(y)) # 결측값 유무 확인
[1] 1 2 3 NA
[1] FALSE FALSE FALSE TRUE
x = c(1,2,NA,3)
print(mean(x))
print(mean(x, na.rm=1)) # 결측값 제거 후 평균 산출
[1] NA
[1] 2
3. 이상값 검색
표준정규분포에서 100개 난수 추출 후 박스플롯 출력
x = rnorm(100)
plot(x)
boxplot(x)
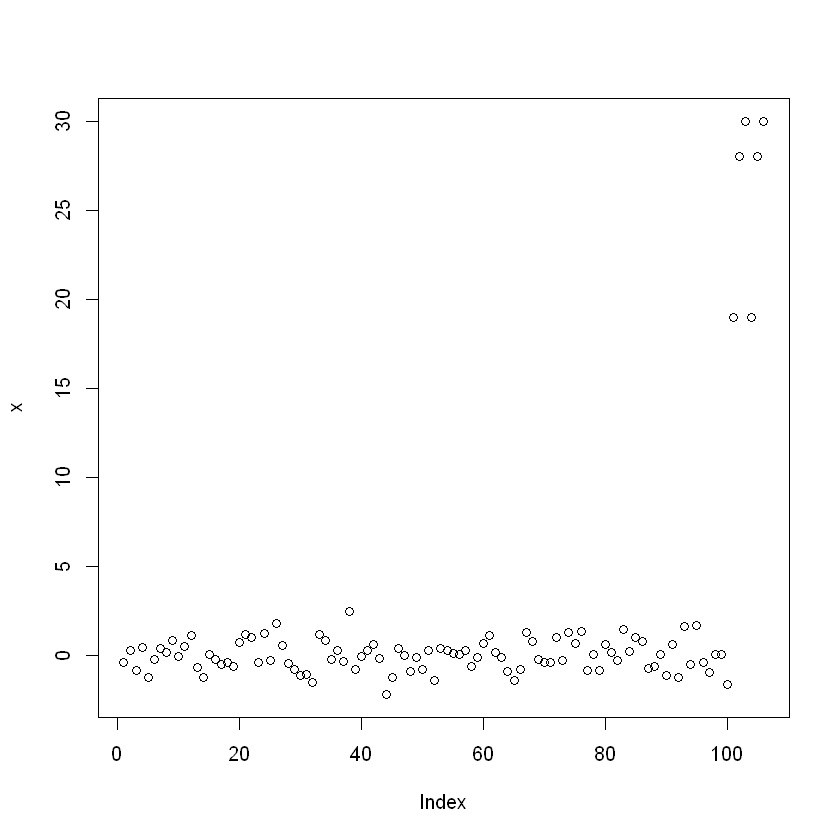
이상치 추가하여 박스플롯 출력
x = c(x, 19,28,30)
plot(x)
print(boxplot(x)$out) # 이상치 출력
[1] 19 28 30 19 28 30
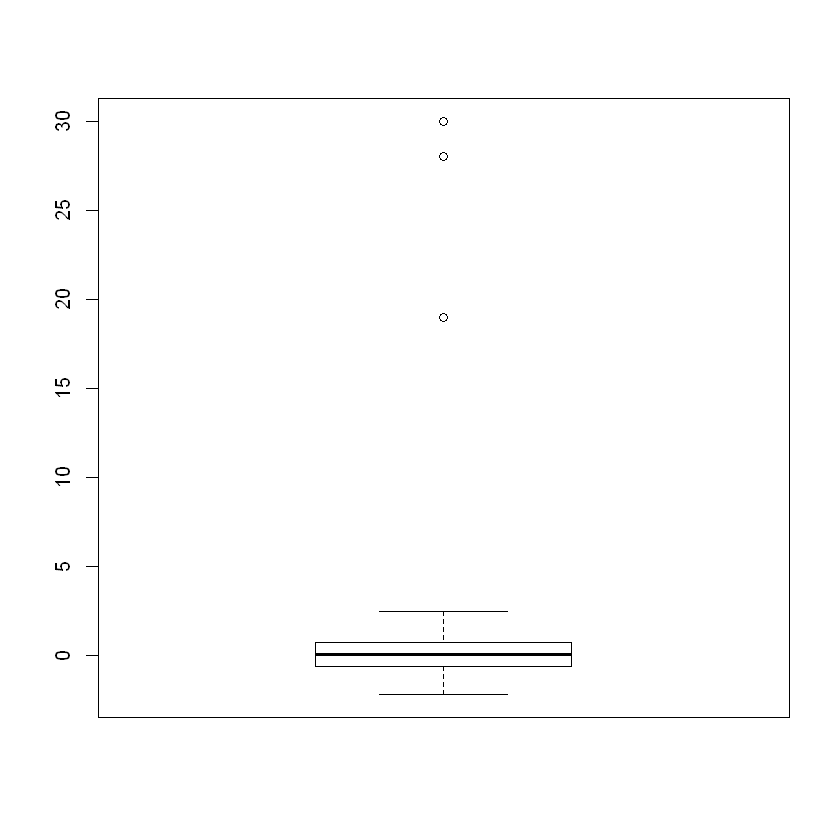
‘outliers’ 패키지 설치 및 불러오기
install.packages("outliers")
library(outliers)
Installing package into 'C:/Users/wooil/Documents/R/win-library/3.6'
(as 'lib' is unspecified)
package 'outliers' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\wooil\AppData\Local\Temp\Rtmpg7GsWG\downloaded_packages
set.seed(1234)
y=rnorm(100)
평균과 가장 차이가 많이 나는 값 출력
print(outlier(y))
[1] 2.548991
반대방향으로 가장 차이가 많이 나는 값 출력
print(outlier(y, opposite=TRUE))
[1] -2.345698
20행, 5열 행렬 생성
dim(y) = c(20,5)
print(dim(y))
[1] 20 5
각 열의 평균과 가장 차이가 많은 값을 각 열별로 출력
print(outlier(y))
[1] 2.415835 1.102298 1.647817 2.548991 2.121117
각 열별로 반대 방향으로 열 평균과 가장 차이가 많은 값 출력
print(outlier(y, opposite = TRUE))
[1] -2.345698 -2.180040 -1.806031 -1.390701 -1.372302
박스플롯
boxplot(y)
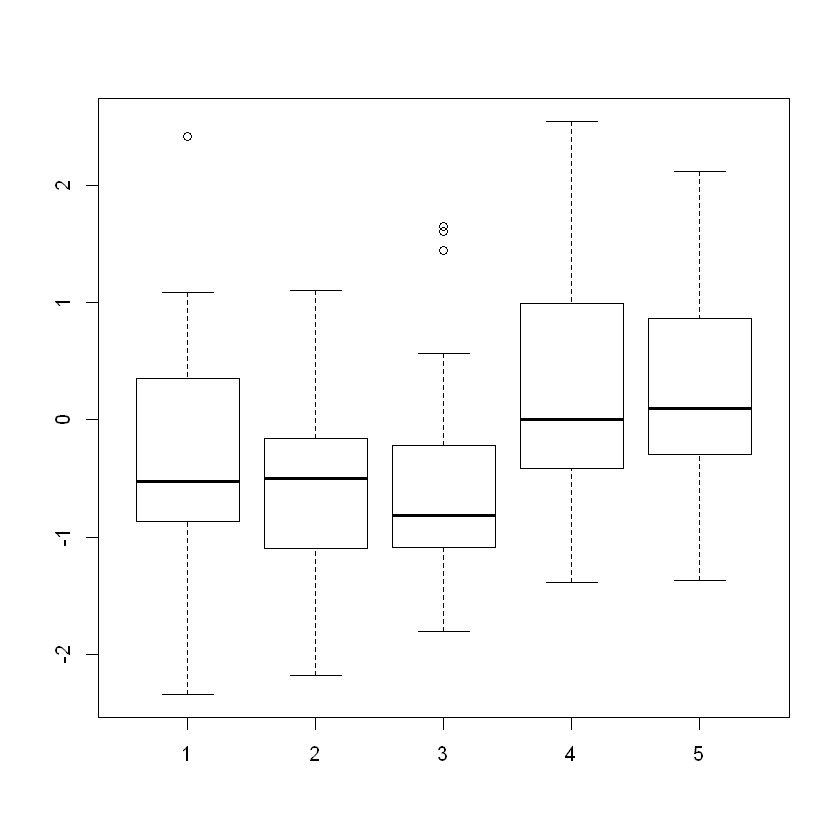
댓글남기기