Whisper API Python 사용법
파이썬으로 쉽게 Whisper API(Speech to text)를 사용할 수 있습니다. 먼저 Whisper API가 무엇인지 알아보고, 파이썬으로 이 API를 사용할 수 있는 방법에 대해 살펴보겠습니다.
Whisper API란?
Whisper API는 2023년 3월에 출시된 오픈AI의 새로운 서비스입니다. 이 API를 사용하면 음성을 텍스트로 변환하는 기능을 앱이나 제품에 쉽게 통합할 수 있습니다. 다만, API 사용은 유료이며, 텍스트로 변환하려는 음성 파일의 길이(분당 $0.006(약 8원))에 따라 과금됩니다.
- API 사용요금
- Model: Whisper
- Usage: $0.006 / minute (rounded to the nearest second)
openai 라이브러리 설치하기
‘openai’는 오픈AI에서 제공하는 Whisper API를 파이썬으로 사용할 수 있도록 해주는 라이브러리입니다. 이외에도 ChatGPT와 같은 대화형 AI와 DALL-E와 같은 이미지 생성 AI의 API도 이용할 수 있습니다. (참고 ChatGPT API Python 사용법 (feat.DALL-E, Karlo))
그럼 openai를 설치하기 위해 명령 프롬프트(CMD)나 터미널에서 다음 명령어를 입력합니다.
pip install openai
오픈AI의 API 키 발급받기
오픈AI 플랫폼에 접속해 회원가입 후 로그인합니다. 화면 우측 상단의 ‘프로필’ -‘View API Keys’를 클릭합니다.
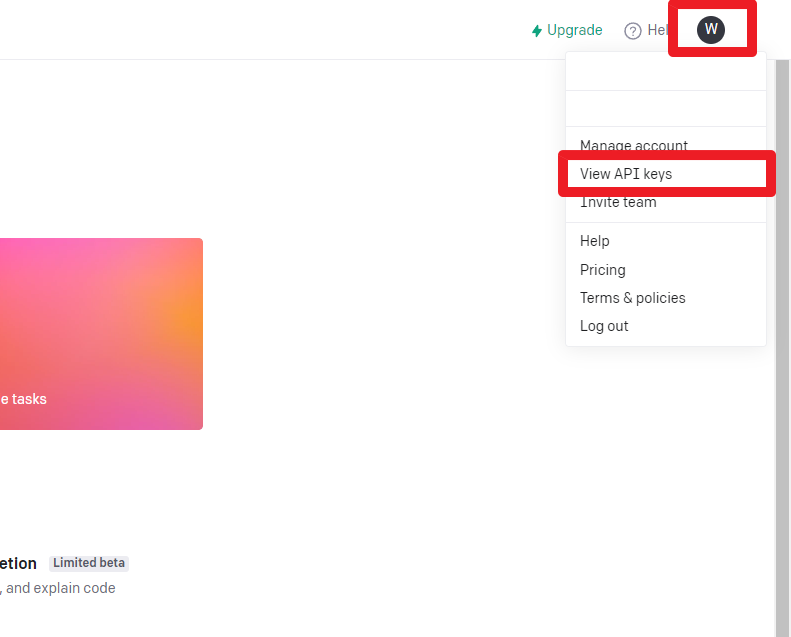
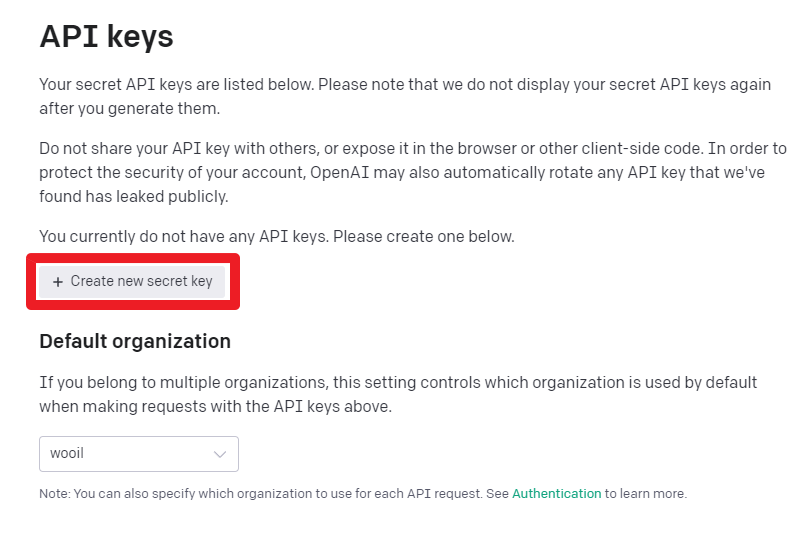
‘Create new secret key’ 버튼을 클릭합니다.
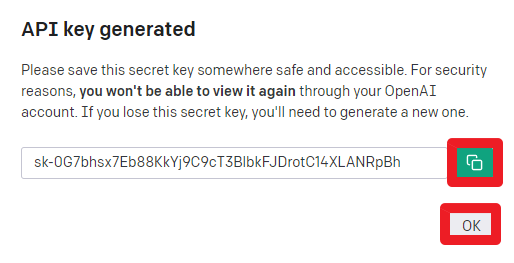
초록색 ‘복사’ 버튼을 클릭해 인증키를 복사하고 ‘OK’ 버튼을 클릭합니다.
openai 불러오기
오픈AI에서 제공하는 Whisper API를 파이썬으로 이용하기 위해 앞에서 설치한 ‘openai’ 라이브러리를 불러옵니다. 오픈AI에서 발급받은 API 키 값을 ‘OPENAI_API_KEY’ 변수에 할당합니다. 그리고 ‘openai.api_key’에 이 값을 할당합니다.
import openai
# 발급받은 API 키 설정
OPENAI_API_KEY = "오픈AI에서 발급받은 API 키"
# openai API 키 인증
openai.api_key = OPENAI_API_KEY
유튜브 영상 다운로드
텍스트로 변환할 음성 파일이 이미 있다면 이 과정은 생략해도 됩니다. 유튜브에서 음성이 포함된 영상의 URL 주소만 있으면 비디오 파일로 다운로드할 수 있습니다. pytube라는 라이브러리를 사용하면 유튜브 영상을 쉽게 파일로 저장할 수 있습니다.
다음과 같이 명령 프롬프트(CMD)나 터미널에서 pytube를 설치합니다.
pip install pytube
다음은 pytube를 사용해 유튜브 영상을 다운로드하는 코드입니다. 먼저 pytube에서 YouTube 모듈을 불러옵니다. 다운로드 받을 폴더 경로를 DOWNLOAD_FOLDER 변수에 할당합니다. 다운로드 받을 영상의 URL은 url 변수에 할당합니다.
그다음 YouTube 객체를 만들고 url에 해당하는 유튜브 영상 정보를 가져옵니다. YouTube 객체를 이용해 해당 영상의 스트림 중에서 가장 고화질의 스트림 정보를 가져옵니다. 그리고 이를 stream 변수에 저장합니다.
끝으로 stream 객체에서 download() 함수를 호출하면 해당하는 영상 파일을 DOWNLOAD_FOLDER 경로에 다운로드합니다.
from pytube import YouTube
DOWNLOAD_FOLDER = "./whisper"
url = "https://www.youtube.com/watch?v="
yt = YouTube(url)
stream = yt.streams.get_highest_resolution()
stream.download(DOWNLOAD_FOLDER)
비디오 파일을 오디오 파일로 변환하기
텍스트로 변환할 오디오 파일이 이미 있다면 이 과정 역시 생략해도 됩니다. 앞서 다운로드한 비디오 파일을 오디오 파일로 변환하면 Whisper API를 사용하기 위한 준비가 끝이 납니다. moviepy라는 라이브러리를 사용하면 비디오 파일을 오디오 파일로 쉽게 편환할 수 있습니다.
다음과 같이 명령 프롬프트(CMD)나 터미널에서 moviepy를 설치합니다.
pip install moviepy
다음은 moviepy를 사용해 비디오 파일에서 오디오를 추출해 파일로 저장하는 코드입니다. 먼저 moviepy에서 VideoFileClip 모듈을 불러옵니다. 동영상 파일 경로를 video_file_path 변수에 할당합니다. 이 video_file_path 경로에 있는 비디오 파일을 video 변수에 저장합니다.
그다음 오디오 파일을 저장할 경로를 audio_file_path 변수에 할당합니다.
끝으로 video.audio.write_audiofile() 함수를 호출하면 해당하는 비디오 파일에서 오디오를 추출하여 audio_file_path 경로에 저장할 수 있습니다.
from moviepy.editor import VideoFileClip
video_file_path = "./whisper/video.mp4"
video = VideoFileClip(video_file_path)
audio_file_path = "./whisper/audio.mp3"
video.audio.write_audiofile(audio_file_path)
오디오 파일 불러오기
텍스트로 변환할 오디오 파일을 불러옵니다.
audio_file = open("./whisper/audio.mp3", "rb")
오디오 파일을 텍스트 파일로 변환하기
다음은 Whisper API를 사용해 오디오 파일에서 자동으로 음성을 인식해 텍스트로 변환하는 작업을 수행하는 코드입니다.
openai.Audio.transcribe() 함수를 호출하여 ‘whisper-1’이라는 이름의 모델을 사용해 해당 오디오 파일에서 transcription을 수행합니다. 결과는 transcript 변수에 할당됩니다.
끝으로 transcription 결과에서 텍스트만 추출해 text 변수에 할당하고 이를 출력합니다.
transcript = openai.Audio.transcribe("whisper-1", audio_file)
text = transcript['text']
print(text)
오디오 파일을 영문 텍스트 파일로 변환하기
다음은 Whisper API를 사용해 오디오 파일에서 자동으로 음성을 인식하고 이를 영어로 번역하는 코드입니다.
openai.Audio.translate() 함수를 호출하여 ‘whisper-1’이라는 이름의 모델을 사용해 해당 오디오 파일에서 transcription을 수행하고, 이를 영어로 번역합니다. 결과는 transcript 변수에 할당됩니다.
결과에서 영어 텍스트만 추출해 text_eng 변수에 할당하고 이를 출력합니다.
transcript = openai.Audio.translate("whisper-1", audio_file)
text_eng = transcript['text']
print(text_eng)
댓글남기기