네이버 데이터랩 오픈 API 서비스
네이버 데이터랩 오픈 API 서비스를 이용하면 Pandas DataFrame 형태로 검색어 트렌드 관련 데이터를 불러올 수 있다. 총 5개 주제어에 대한 검색어 그룹을 지정할 수 있고, 각 검색어 그룹은 주제어에 해당하는 최대 20개의 검색어를 배열로 설정할 수 있다. 또, PC 혹은 모바일 환경에 따른 검색어 트렌드를 확인할 수도 있다. 이 외에도 성별, 연령대 별 조건을 추가할 수 있다.
[naver developers - 데이터랩]](https://developers.naver.com/products/service-api/datalab/datalab.md)에서 Open API를 신청할 수 있다. 여기에서는 이미 신청이 완료된 상황을 가정한다.파이썬 상에서 쉽게 Open API 서비스를 활용할 수 있도록 돕는 컨트롤러를 만들어 볼 것이다. 추가적으로 불러온 데이터를 시각화해보고, fbprophet라이브러리를 이용해 가까운 미래의 검색어 그룹별 트렌드를 예측해보자.
참고
PyNaver는 naver developers에서 제공하는 오픈 API를 이용할 수 있는 Python Client이다. PyNaver를 설치한 경우 아래와 같이 직접 API 클래스를 구현하지 않아도 된다.
필요한 라이브러리 불러오기
Open API 컨트롤러가 정상적으로 동작할 수 있도록 하기 위해 아래와 같이 필요 라이브러리를 import 한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
import urllib.request
import datetime
import json
import glob
import sys
import os
from fbprophet import Prophet
import warnings
warnings.filterwarnings(action='ignore')
%matplotlib inline
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.grid'] = False
pd.set_option('display.max_columns', 250)
pd.set_option('display.max_rows', 250)
pd.set_option('display.width', 100)
pd.options.display.float_format = '{:.2f}'.format
네이버 데이터랩 오픈 API 컨트롤러 클래스 만들기
파이썬 상에서 Open API 서비스를 활용하기 위해 컨트롤러 클래스를 만든다. Naver Developers의 Application에 접속하여 Application 목록에서 신청한 서비스를 클릭한다. 애플리케이션 정보에 있는 Client ID와 Client Secret 값을 바탕으로 클래스를 초기화하도록 설정한다.
class NaverDataLabOpenAPI():
"""
네이버 데이터랩 오픈 API 컨트롤러 클래스
"""
def __init__(self, client_id, client_secret):
"""
인증키 설정 및 검색어 그룹 초기화
"""
self.client_id = client_id
self.client_secret = client_secret
self.keywordGroups = []
self.url = "https://openapi.naver.com/v1/datalab/search"
1) 검색어 그룹 추가 기능
컨트롤러 객체를 생성하면 self.keywordGroups라는 빈 리스트가 생긴다. 검색어 그룹을 미리 Dictionary 객체에 정의한 다음 아래 메서드를 이용해 self.keywordGroups리스트에 추가할 수 있다. 검색어 그룹은 최대 5개 까지 설정할 수 있다.
def add_keyword_groups(self, group_dict):
"""
검색어 그룹 추가
"""
keyword_gorup = {
'groupName': group_dict['groupName'],
'keywords': group_dict['keywords']
}
self.keywordGroups.append(keyword_gorup)
print(f">>> Num of keywordGroups: {len(self.keywordGroups)}")
2) 데이터 요청 기능
| 파라미터 | 타입 | 설명 |
|---|---|---|
| startDate | str | 조회 기간 시작 날짜(yyyy-mm-dd 형식) 2016년 1월 1일부터 조회 가능 |
| endDate | str | 조회 기간 종료 날짜(yyyy-mm-dd 형식) |
| timeUnit | str | 구간 단위 date: 일간 week: 주간 month: 월간 |
| device | str | 범위. 검색 환경에 따른 조건 설정 안 함: 모든 환경 pc: PC에서 검색 추이 mo: 모바일에서 검색 추이 |
| ages | list | 연령. 검색 사용자의 연령에 따른 조건 설정 안 함: 모든 연령 1: 0∼12세 2: 13∼18세 3: 19∼24세 4: 25∼29세 5: 30∼34세 6: 35∼39세 7: 40∼44세 8: 45∼49세 9: 50∼54세 10: 55∼59세 11: 60세 이상 |
| gender | str | 성별. 검색 사용자의 성별에 따른 조건 설정 안 함: 모든 성별 m: 남성 f: 여성 |
위 테이블에 설명되어 있는 요청 파라미터들을 설정하고, 아래 메서드에 입력하면 DataFrame 형태로 데이터를 불러올 수 있다.
def get_data(self, startDate, endDate, timeUnit, device, ages, gender):
"""
요청 결과 반환
"""
# Request body
body = json.dumps({
"startDate": startDate,
"endDate": endDate,
"timeUnit": timeUnit,
"keywordGroups": self.keywordGroups,
"device": device,
"ages": ages,
"gender": gender
}, ensure_ascii=False)
# Results
request = urllib.request.Request(self.url)
request.add_header("X-Naver-Client-Id",self.client_id)
request.add_header("X-Naver-Client-Secret",self.client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
# Json Result
result = json.loads(response.read())
df = pd.DataFrame(result['results'][0]['data'])[['period']]
for i in range(len(self.keywordGroups)):
tmp = pd.DataFrame(result['results'][i]['data'])
tmp = tmp.rename(columns={'ratio': result['results'][i]['title']})
df = pd.merge(df, tmp, how='left', on=['period'])
self.df = df.rename(columns={'period': '날짜'})
self.df['날짜'] = pd.to_datetime(self.df['날짜'])
else:
print("Error Code:" + rescode)
return self.df
3) 일 별 검색어 트렌드 그래프 출력 기능
def plot_daily_trend(self):
"""
일 별 검색어 트렌드 그래프 출력
"""
colList = self.df.columns[1:]
n_col = len(colList)
fig = plt.figure(figsize=(12,6))
plt.title('일 별 검색어 트렌드', size=20, weight='bold')
for i in range(n_col):
sns.lineplot(x=self.df['날짜'], y=self.df[colList[i]], label=colList[i])
plt.legend(loc='upper right')
return fig
4) 월 별 검색어 트렌드 그래프 출력 기능
def plot_monthly_trend(self):
"""
월 별 검색어 트렌드 그래프 출력
"""
df = self.df.copy()
df_0 = df.groupby(by=[df['날짜'].dt.year, df['날짜'].dt.month]).mean().droplevel(0).reset_index().rename(columns={'날짜': '월'})
df_1 = df.groupby(by=[df['날짜'].dt.year, df['날짜'].dt.month]).mean().droplevel(1).reset_index().rename(columns={'날짜': '년도'})
df = pd.merge(df_1[['년도']], df_0, how='left', left_index=True, right_index=True)
df['날짜'] = pd.to_datetime(df[['년도','월']].assign(일=1).rename(columns={"년도": "year", "월":'month','일':'day'}))
colList = df.columns.drop(['날짜','년도','월'])
n_col = len(colList)
fig = plt.figure(figsize=(12,6))
plt.title('월 별 검색어 트렌드', size=20, weight='bold')
for i in range(n_col):
sns.lineplot(x=df['날짜'], y=df[colList[i]], label=colList[i])
plt.legend(loc='upper right')
return fig
5) fbprophet을 이용한 검색어 그룹 별 시계열 트렌드 예측 그래프 출력 기능
days 파라미터에 예측일수를 입력하면, 시계열 예측 결과를 시각화해볼 수 있다.
def plot_pred_trend(self, days):
"""
검색어 그룹 별 시계열 트렌드 예측 그래프 출력
days: 예측일수
"""
colList = self.df.columns[1:]
n_col = len(colList)
fig_list = []
for i in range(n_col):
globals()[f"df_{str(i)}"] = self.df[['날짜', f'{colList[i]}']]
globals()[f"df_{str(i)}"] = globals()[f"df_{str(i)}"].rename(columns={'날짜': 'ds', f'{colList[i]}': 'y'})
m = Prophet()
m.fit(globals()[f"df_{str(i)}"])
future = m.make_future_dataframe(periods=days)
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
globals()[f"fig_{str(i)}"] = m.plot(forecast, figsize=(12,6))
plt.title(colList[i], size=20, weight='bold')
fig_list.append(globals()[f"fig_{str(i)}"])
return fig_list
데이터 불러오기
1) 검색어 그룹 세트 정의하기
keyword_group_set = {
'keyword_group_1': {'groupName': "애플", 'keywords': ["애플","Apple","AAPL"]},
'keyword_group_2': {'groupName': "아마존", 'keywords': ["아마존","Amazon","AMZN"]},
'keyword_group_3': {'groupName': "구글", 'keywords': ["구글","Google","GOOGL"]},
'keyword_group_4': {'groupName': "테슬라", 'keywords': ["테슬라","Tesla","TSLA"]},
'keyword_group_5': {'groupName': "페이스북", 'keywords': ["페이스북","Facebook","FB"]}
}
2) 데이터 요청하기
# API 인증 정보 설정
client_id = "4bWeJL4gcxY6QX7ZJEF4"
client_secret = "z4TaBAhwUR"
# 요청 파라미터 설정
startDate = "2020-01-01"
endDate = "2020-12-31"
timeUnit = 'date'
device = ''
ages = []
gender = ''
# 데이터 프레임 정의
naver = NaverDataLabOpenAPI(client_id=client_id, client_secret=client_secret)
naver.add_keyword_groups(keyword_group_set['keyword_group_1'])
naver.add_keyword_groups(keyword_group_set['keyword_group_2'])
naver.add_keyword_groups(keyword_group_set['keyword_group_3'])
naver.add_keyword_groups(keyword_group_set['keyword_group_4'])
naver.add_keyword_groups(keyword_group_set['keyword_group_5'])
df = naver.get_data(startDate, endDate, timeUnit, device, ages, gender)
>>> Num of keywordGroups: 1
>>> Num of keywordGroups: 2
>>> Num of keywordGroups: 3
>>> Num of keywordGroups: 4
>>> Num of keywordGroups: 5
3) DataFrame 확인하기
df.head()
| 날짜 | 애플 | 아마존 | 구글 | 테슬라 | 페이스북 | |
|---|---|---|---|---|---|---|
| 0 | 2020-01-01 | 2.89 | 1.36 | 56.16 | 1.37 | 32.61 |
| 1 | 2020-01-02 | 3.28 | 1.67 | 62.64 | 1.43 | 30.05 |
| 2 | 2020-01-03 | 3.16 | 1.61 | 61.69 | 1.47 | 29.34 |
| 3 | 2020-01-04 | 2.99 | 1.40 | 59.07 | 1.47 | 28.64 |
| 4 | 2020-01-05 | 2.99 | 1.52 | 59.56 | 1.69 | 28.91 |
df.tail()
| 날짜 | 애플 | 아마존 | 구글 | 테슬라 | 페이스북 | |
|---|---|---|---|---|---|---|
| 361 | 2020-12-27 | 5.81 | 2.01 | 61.27 | 3.01 | 23.81 |
| 362 | 2020-12-28 | 7.72 | 2.25 | 66.38 | 4.23 | 24.57 |
| 363 | 2020-12-29 | 8.86 | 2.48 | 66.48 | 4.76 | 23.73 |
| 364 | 2020-12-30 | 8.17 | 2.31 | 63.74 | 4.35 | 23.64 |
| 365 | 2020-12-31 | 6.99 | 1.94 | 58.65 | 4.59 | 23.93 |
4) 일 별 트렌드 시각화하기
fig_1 = naver.plot_daily_trend()
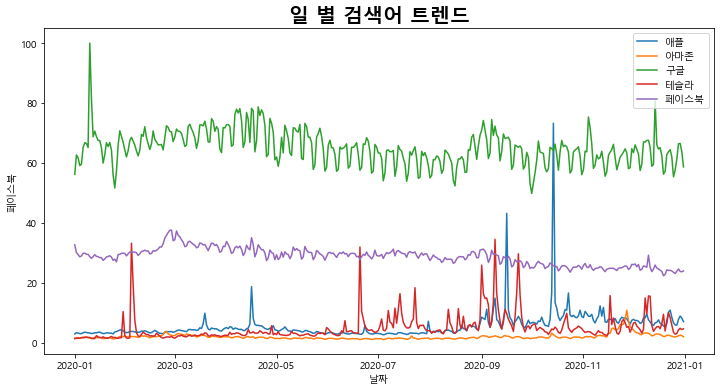
5) 월 별 트렌드 시각화하기
fig_2 = naver.plot_monthly_trend()
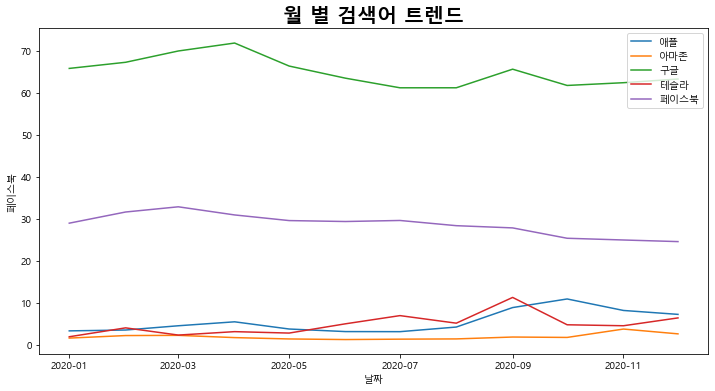
6) 트렌드 예측하기
fig_3 = naver.plot_pred_trend(days = 90)
INFO:fbprophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet:Disabling yearly seasonality. Run prophet with yearly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
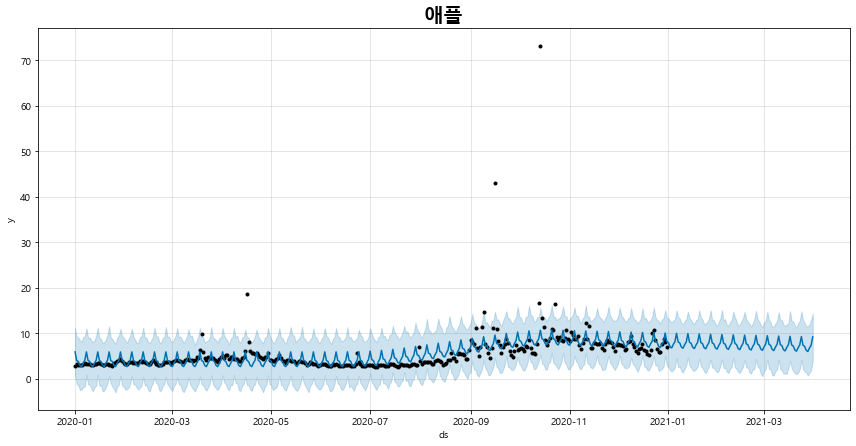
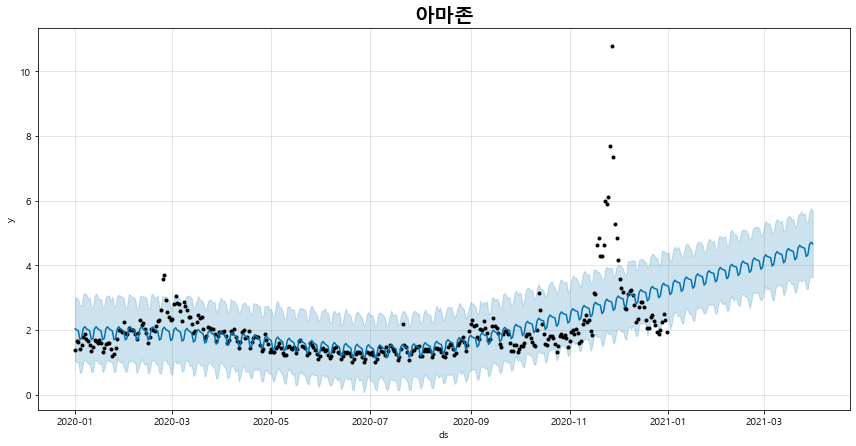
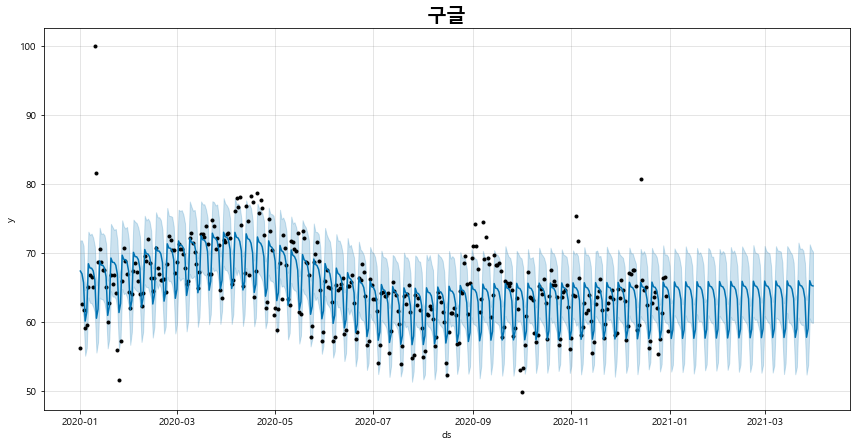
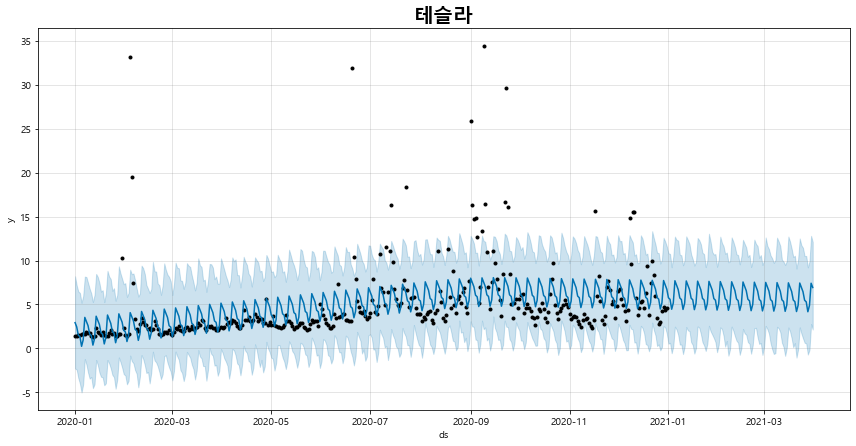
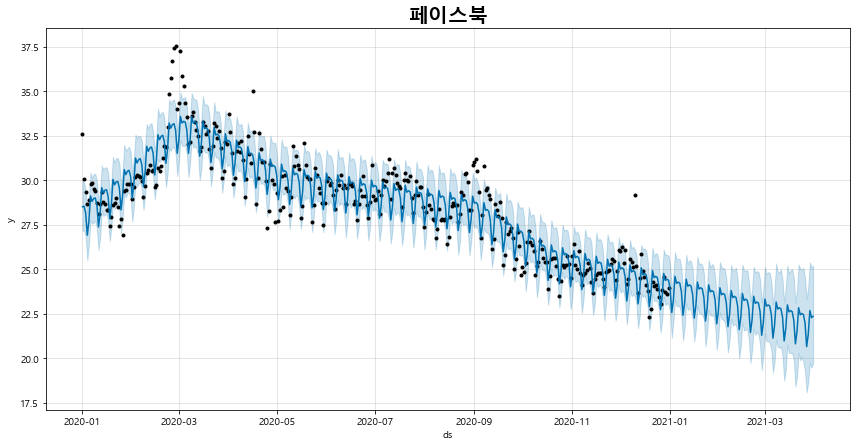
전체 소스 코드
class NaverDataLabOpenAPI():
"""
네이버 데이터랩 오픈 API 컨트롤러 클래스
"""
def __init__(self, client_id, client_secret):
"""
인증키 설정 및 검색어 그룹 초기화
"""
self.client_id = client_id
self.client_secret = client_secret
self.keywordGroups = []
self.url = "https://openapi.naver.com/v1/datalab/search"
def add_keyword_groups(self, group_dict):
"""
검색어 그룹 추가
"""
keyword_gorup = {
'groupName': group_dict['groupName'],
'keywords': group_dict['keywords']
}
self.keywordGroups.append(keyword_gorup)
print(f">>> Num of keywordGroups: {len(self.keywordGroups)}")
def get_data(self, startDate, endDate, timeUnit, device, ages, gender):
"""
요청 결과 반환
timeUnit - 'date', 'week', 'month'
device - None, 'pc', 'mo'
ages = [], ['1' ~ '11']
gender = None, 'm', 'f'
"""
# Request body
body = json.dumps({
"startDate": startDate,
"endDate": endDate,
"timeUnit": timeUnit,
"keywordGroups": self.keywordGroups,
"device": device,
"ages": ages,
"gender": gender
}, ensure_ascii=False)
# Results
request = urllib.request.Request(self.url)
request.add_header("X-Naver-Client-Id",self.client_id)
request.add_header("X-Naver-Client-Secret",self.client_secret)
request.add_header("Content-Type","application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
# Json Result
result = json.loads(response.read())
df = pd.DataFrame(result['results'][0]['data'])[['period']]
for i in range(len(self.keywordGroups)):
tmp = pd.DataFrame(result['results'][i]['data'])
tmp = tmp.rename(columns={'ratio': result['results'][i]['title']})
df = pd.merge(df, tmp, how='left', on=['period'])
self.df = df.rename(columns={'period': '날짜'})
self.df['날짜'] = pd.to_datetime(self.df['날짜'])
else:
print("Error Code:" + rescode)
return self.df
def plot_daily_trend(self):
"""
일 별 검색어 트렌드 그래프 출력
"""
colList = self.df.columns[1:]
n_col = len(colList)
fig = plt.figure(figsize=(12,6))
plt.title('일 별 검색어 트렌드', size=20, weight='bold')
for i in range(n_col):
sns.lineplot(x=self.df['날짜'], y=self.df[colList[i]], label=colList[i])
plt.legend(loc='upper right')
return fig
def plot_monthly_trend(self):
"""
월 별 검색어 트렌드 그래프 출력
"""
df = self.df.copy()
df_0 = df.groupby(by=[df['날짜'].dt.year, df['날짜'].dt.month]).mean().droplevel(0).reset_index().rename(columns={'날짜': '월'})
df_1 = df.groupby(by=[df['날짜'].dt.year, df['날짜'].dt.month]).mean().droplevel(1).reset_index().rename(columns={'날짜': '년도'})
df = pd.merge(df_1[['년도']], df_0, how='left', left_index=True, right_index=True)
df['날짜'] = pd.to_datetime(df[['년도','월']].assign(일=1).rename(columns={"년도": "year", "월":'month','일':'day'}))
colList = df.columns.drop(['날짜','년도','월'])
n_col = len(colList)
fig = plt.figure(figsize=(12,6))
plt.title('월 별 검색어 트렌드', size=20, weight='bold')
for i in range(n_col):
sns.lineplot(x=df['날짜'], y=df[colList[i]], label=colList[i])
plt.legend(loc='upper right')
return fig
def plot_pred_trend(self, days):
"""
검색어 시계열 트렌드 예측 그래프 출력
days: 예측일수
"""
colList = self.df.columns[1:]
n_col = len(colList)
fig_list = []
for i in range(n_col):
globals()[f"df_{str(i)}"] = self.df[['날짜', f'{colList[i]}']]
globals()[f"df_{str(i)}"] = globals()[f"df_{str(i)}"].rename(columns={'날짜': 'ds', f'{colList[i]}': 'y'})
m = Prophet()
m.fit(globals()[f"df_{str(i)}"])
future = m.make_future_dataframe(periods=days)
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
globals()[f"fig_{str(i)}"] = m.plot(forecast, figsize=(12,6))
plt.title(colList[i], size=20, weight='bold')
fig_list.append(globals()[f"fig_{str(i)}"])
return fig_list
댓글남기기